Chapter 7 - Advanced Computer Graphics¶
Chapter 3 introduced fundamental concepts of computer graphics. A major topic in that chapter was how to represent and render geometry using surface primitives such as points, lines, and polygons. In this chapter our primary focus is on volume graphics. Compared to surface graphics, volume graphics has a greater expressive range in its ability to render inhomogeneous materials, and is a dominant technique for visualizing 3D image (volume) datasets.
We begin the chapter by describing two techniques that are important to both surface and volume graphics. These are simulating object transparency using simple blending functions, and using texture maps to add realism without excessive computational cost. We also describe various problems and challenges inherent to these techniques. We then follow with a focused discussion on volume graphics, including both object-order and image-order techniques, illumination models, approaches to mixing surface and volume graphics, and methods to improve performance. Finally, the chapter concludes with an assortment of important techniques for creating more realistic visualizations. These techniques include stereo viewing, anti-aliasing, and advanced camera techniques such as motion blur, focal blur, and camera motion.
7.1 Transparency and Alpha Values¶
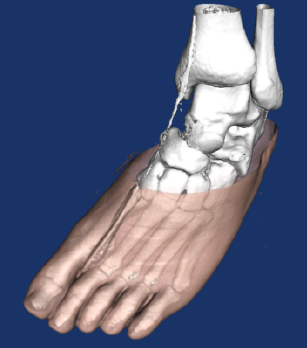
Up to this point in the text we have focused on rendering opaque objects --- that is, we have assumed that objects reflect, scatter, or absorb light at their surface, and no light is transmitted through to their interior. Although rendering opaque objects is certainly useful, there are many applications that can benefit from the ability to render objects that transmit light. One important application of transparency is volume rendering, which we will explore in greater detail later in the chapter. Another simple example makes objects translucent so that we can see inside of the region bounded by the surface, as shown in Figure 12-4). As demonstrated in this example, by making the skin semi-transparent, it becomes possible to see the internal organs.
Transparency and its complement, opacity, are often referred to as alpha in computer graphics. For example, a polygon that is 50 percent opaque will have an alpha value of 0.5 on a scale from zero to one. An alpha value of one represents an opaque object and zero represents a completely transparent object. Frequently, alpha is specified as a property for the entire actor, but it also can be done on a vertex basis just like colors. In such cases, the RGB specification of a color is extended to RGBA where A represents the alpha component. On many graphics cards the frame buffer can store the alpha value along with the RGB values. More typically, an application will request storage for only red, green, and blue on the graphics card and use back-to-front blending to avoid the need for storing alpha.
Unfortunately, having transparent actors introduces some complications into the rendering process. If you think back to the process of ray tracing, viewing rays are projected from the camera out into the world, where they intersect the first actor they come to. With an opaque actor, the lighting equations are applied and the resulting color is drawn to the screen. With a semi-transparent actor we must solve the lighting equations for this actor, and then continue projecting the ray farther to see if it intersects any other actors. The resulting color is a composite of all the actors it has intersected. For each surface intersection this can be expressed as Equation7-1.
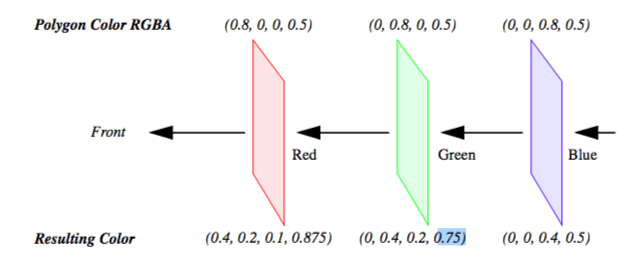
In this equation subscript s refers to the surface of the actor, while subscript b refers to what is behind the actor. The term is called-- the transmissivity, and represents the amount of light that is transmitted through the actor. As an example, consider starting with three polygons colored red, green, and blue each with a transparency of 0.5. If the red polygon is in the front and the background is black, the resulting RGBA color will be (0.4, 0.2, 0.1, 0.875) on a scale from zero to one (Figure 7-1).
It is important to note that if we switch the ordering of the polygons, the resulting color will change. This underlies a major technical problem in using transparency. If we ray-trace a scene, we will intersect the surfaces in a well-defined manner --- from front to back. Using this knowledge we can trace a ray back to the last surface it intersects, and then composite the color by applying Equation7-1 to all the surfaces in reverse order (i.e., from back to front). In object order rendering methods, this compositing is commonly supported in hardware, but unfortunately we are not guaranteed to render the polygons in any specific order. Even though our polygons are situated as in Figure 7-1, the order in which the polygons are rendered might be the blue polygon, followed by the red, and finally the green polygon. Consequently, the resulting color is incorrect.
If we look at the RGBA value for one pixel we can see the problem. When the blue polygon is rendered, the frame buffer and z-buffer are empty, so the RGBA quad (0,0,0.8,0.5) is stored along with the its z-buffer value. When the red polygon is rendered, a comparison of its z-value and the current z-buffer indicates that it is in front of the previous pixel entry. So Equation 7-1 is applied using the frame buffer's RGBA value. This results in the RGBA value (0.4,0,0.2,0.75) being written to the buffer. Now, the green polygon is rendered and the z comparison indicates that it is behind the current pixel's value. Again this equation is applied, this time using the frame buffer's RGBA value for the surface and the polygon's values from behind. This results in a final pixel color of (0.3,0.2, 0.175,0.875), which is different from what we previously calculated. Once the red and blue polygons have been composited and written to the frame buffer, there is no way to insert the final green polygon into the middle where it belongs.
One solution to this problem is to sort the polygons from back to front and then render them in this order. Typically, this must be done in software requiring additional computational overhead. Sorting also interferes with actor properties (such as specular power), which are typically sent to the graphics engine just before rendering the actor's polygons. Once we start mixing up the polygons of different actors, we must make sure that the correct actor properties are set for each polygon rendered.
Another solution is to store more than one set of RGBAZ values in the frame buffer. This is costly because of the additional memory requirements, and is still limited by the number of RGBAZ values you can store. Some new techniques use a combination of multiple RGBAZ value storage and multi-pass rendering to yield correct results with a minimum performance hit [Hodges92].
The second technical problem with rendering transparent objects occurs less frequently, but can still have disastrous effects. In certain applications, such as volume rendering, it is desirable to have thousands of polygons with small alpha values. If the RGBA quad is stored in the frame buffer as four eight-bit values, then the round-off can accumulate over many polygons, resulting in gross errors in the output image. This may be less of a problem in the future if graphics hardware begins to store 16 or more bits per component for texture and the frame buffer.
7.2 Texture Mapping¶
Texture mapping is a technique to add detail to an image without requiring modelling detail. Texture mapping can be thought of as pasting a picture to the surface of an object. The use of texture mapping requires two pieces of information: a texture map and texture coordinates. The texture map is the picture we paste, and the texture coordinates specify the location where the picture is pasted. More generally, texture mapping is a table lookup for color, intensity, and/or transparency that is applied to an object as it is rendered. Textures maps and coordinates are most often two-dimensional, but three-dimensional texture maps and coordinates are supported by most new graphics hardware.
The value of texture mapping can be shown through the simple example of rendering a wooden table. The basic geometry of a table can be easily created, but achieving the wood grain details is difficult. Coloring the table brown is a good start, but the image is still unrealistic. To simulate the wood grain we need to have many small color changes across the surface of the table. Using vertex colors would require us to have millions of extra vertices just to get the small color changes. The solution to this is to apply a wood grain texture map to the original polygons. This is like applying an oak veneer onto inexpensive particle board, and this is the strategy used by video games to provide realistic scenes with low numbers of polygons for interactivity.
There are several ways in which we can apply texture data. For each pixel in the texture map (commonly called a texel for texture element), there may be one to four components that affect how the texture map is pasted onto the surface of the underlying geometry. A texture map with one component is called an intensity map. Applying an intensity map results in changes to the intensity (or value in HSV) of the resulting pixels. If we took a gray scale image of wood grain, and then texture-mapped it onto a brown polygon, we would have a reasonable looking table. The hue and saturation of the polygon would still be determined by the brown color, but the intensity would be determined from the texture map. A better looking table could be obtained by using a color image of the wood. This is a three component texture map, where each texel is represented as a RGB trip-let. Using an RGB map allows us to obtain more realistic images, since we would have more than just the intensity changes of the wood.
By adding alpha values to an intensity map we get two components. We can do the same to an RGB texture map to get a four component RGBA texture map. In these cases, the alpha value can be used to make parts of the underlying geometry transparent. A common trick in computer graphics is to use RGBA textures to render trees. Instead of trying to model the complex geometry of a tree, we just render a rectangle with an RGBA texture map applied to it. Where there are leaves or branches, the alpha is one, where there are gaps and open space, the alpha is zero. As a result, we can see through portions of the rectangle, giving the illusion of viewing through the branches and leaves of a tree.
Besides the different ways in which a texture map can be defined, there are options in how it interacts with the original color of the object. A common option for RGB and RGBA maps is to ignore the original color; that is, just apply the texture color as specified. Another option is to modulate the original color by the texture map color (or intensity) to produce the final color.
While we have been focusing on 2D texture maps, they can be of any dimension, though the most common are 2D and 3D. Three-dimensional texture maps are used for textures that are a function of 3D space, such as wood grain, stone, or X-ray intensity (i.e., CT scan). In fact, a volumetric dataset is essentially a 3D texture. We can perform high-speed volume rendering by passing planes through a 3D texture and compositing them using translucent alpha values in the correct order.
Techniques for performing volume rendering using texture mapping hardware will be discussed later in this chapter.
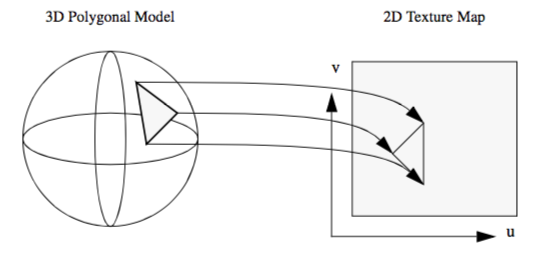
A fundamental step in the texture mapping process is determining how to map the texture onto the geometry. To accomplish this, each vertex has an associated texture coordinate in addition to its position, surface normal, color, and other point attributes. The texture coordinate maps the vertex into the texture map as shown in Figure 7-2. The texture coordinate system uses the parameters (u,v) and (u,v,t) or equivalently (r,s) or (r,s,t) for specifying 2D and 3D texture values. Points between the vertices are linearly interpolated to determine texture map values.
Another approach to texture mapping uses procedural texture definitions instead of a texture map. In this approach, as geometry is rendered, a procedure is called for each pixel to calculate a texel value. Instead of using the (u,v,t) texture coordinates to index into an image, they are passed as arguments to the procedural texture that uses them to calculate its result. This method provides almost limitless flexibility in the design of a texture; therefore, it is almost impossible to implement in dedicated hardware. Most commonly, procedural textures are used with software rendering systems that do not make heavy use of existing graphics hardware.
While texture maps are generally used to add detail to rendered images, there are important visualization applications.
-
Texture maps can be generated procedurally as a function of data. One example is to change the appearance of a surface based on local data value.
-
Texture coordinates can be generated procedurally as a function of data. For example, we can threshold geometry by creating a special texture map and then setting texture coordinates based on local data value. The texture map consists of two entries: fully transparent (\alpha = 0 ) and fully opaque (\alpha = 1). The texture coordinate is then set to index into the transparent portion of the map if the scalar value is less than some threshold, or into the opaque portion otherwise.
-
Texture maps can be animated as a function of time. By choosing a texture map whose intensity varies monotonically from dark to light, and then "moving" the texture along an object, the object appears to crawl in the direction of the texture map motion. We can use this technique to add apparent motion to things like hedgehogs to show vector magnitude. Figure 7-3 is an example of a texture map animation used to simulate vector field motion.
These techniques will be covered in greater detail in Chapter 9. (See "Texture Algorithms" for more information.)
7.3 Volume Rendering¶
Until now we have concentrated on the visualization of data through the use of geometric primitives such as points, lines, and polygons. For many applications such as architectural walk-throughs or terrain visualization, this is obviously the most efficient and effective representation for the data. In contrast, some applications require us to visualize data that is inherently volumetric (which we refer to as 3D image or volume datasets). For example, in biomedical imaging we may need to visualize data obtained from an MR or CT scanner, a confocal microscope, or an ultrasound study. Weather analysis and other simulations also produce large quantities of volumetric data in three or more dimensions that require effective visualization techniques. As a result of the popularity and usefulness of volume data over the last several decades, a broad class of rendering techniques known as volume rendering has emerged. The purpose of volume rendering is to effectively convey information within volumetric data.
In the past, researchers have attempted to define volume rendering as a process that operates directly on the dataset to produce an image without generating an intermediate geometric representation. With recent advances in graphics hardware and clever implementations, developers have been able to use geometric primitives to produce images that are identical to those generated by direct volume rendering techniques. Due to these new techniques, it is nearly impossible to define volume rendering in a manner that is clearly distinct from geometric rendering. Therefore, we choose a broad definition of volume rendering as any method that operates on volumetric data to produce an image.
The next several sections cover a variety of volume rendering methods that use direct rendering techniques, geometric primitive rendering techniques, or a combination of these two methods, to produce an image. Some of the direct volume rendering techniques discussed in this chapter generate images that are nearly identical to those produced by geometric rendering techniques discussed in earlier chapters. For example, using a ray casting method to produce an isosurface image is similar, though not truly equivalent, to rendering geometric primitives that were extracted with the marching cubes contouring technique described in Chapter 6.
The two basic surface rendering approaches described in Chapter 3, image-order and object-order, apply to volume rendering techniques as well. In an image-order method, rays are cast for each pixel in the image plane through the volume to compute pixel values, while in an object-order method the volume is traversed, typically in a front-to-back or back-to-front order, with each voxel processed to determine its contribution to the image. In addition, there are other volume rendering techniques that cannot easily be classified as image-order or object-order. For example, a volume rendering technique may traverse both the image and the volume simultaneously, or the image may be computed in the frequency domain rather than the spatial domain.
Since volume rendering is typically used to generate images that represent an entire 3D dataset in a 2D image, several new challenges are introduced. Classification must be performed to assign color and opacity to regions within the volume, and volumetric illumination models must be defined to support shading. Furthermore, efficiency and compactness are of great importance due to the complexity of volume rendering methods and the size of typical volumetric datasets. A geometric model that consists of one million primitives is generally considered large, while a volumetric dataset with one million voxels is quite small. Typical volumes contain between ten and several hundred million voxels, with datasets of a billion or more voxels becoming more common. Clearly care must be taken when deciding to store auxiliary information at each voxel or to increase the time required to process each voxel.
7.4 Image-Order Volume Rendering¶
Image-order volume rendering is often referred to as ray casting or ray tracing. The basic idea is that we determine the value of each pixel in the image by sending a ray through the pixel into the scene according to the current camera parameters. We then evaluate the data encountered along the ray using some specified function in order to compute the pixel value. As we will demonstrate throughout this chapter, ray casting is a flexible technique that can be used to render any 3D image dataset, and can produce a variety images. Also, it is relatively easy to extend a basic ray casting technique designed for volumetric data sets that have uniform voxels to work on rectilinear or structured grids. Unfortunately, basic ray casting is also fairly slow; therefore, later in this chapter we will discuss a number of acceleration methods that can be used to improve performance, though often with some additional memory requirements or loss in flexibility.
The ray casting process is illustrated in Figure 7-4. This example uses a standard orthographic camera projection; consequently, all rays are parallel to each other and perpendicular to the view plane. The data values along each ray are processed according to the ray function, which in this case determines the maximum value along the ray and converts it to a gray scale pixel value where the minimum scalar value in the volume maps to transparent black, and the maximum scalar value maps to opaque white.
The two main steps of ray casting are determining the values encountered along the ray, and then processing these values according to a ray function. Although in implementation these two steps are typically combined, we will treat them independently for the moment. Since the specific ray function often determines the method used to extract values along the ray, we will begin by considering some of the basic ray function types.
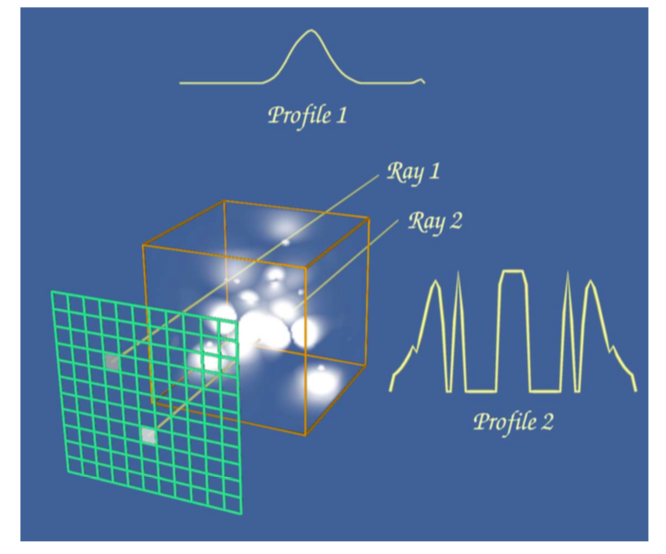
Figure 7-5 shows the data value profile of a ray as it passes through 8 bit volumetric data where the data values can range between 0 and 255. The x-axis of the profile indicates distance from the view plane while the y-axis represents data value. The results obtained from four different simple ray functions are shown below the profile. For display purposes we convert the raw result values to gray scale values using a method similar to the one in the previous example.
The first two ray functions, maximum value and average value, are basic operations on the scalar values themselves. The third ray function computes the distance along the ray at which a scalar value at or above 30 is first encountered, while the fourth uses an alpha compositing technique, treating the values along the ray as samples of opacity accumulated per unit distance. Unlike the first three ray functions, the result of the compositing technique is not a scalar value or distance that can be represented on the ray profile.
The maximum intensity projection, or MIP, is probably the simplest way to visualize volumetric data. This technique is fairly forgiving when it comes to noisy data, and produces images that provide an intuitive understanding of the underlying data. One problem with this method is that it is not possible to tell from a still image where the maximum value occurred along the ray. For example, consider the image of a carotid artery shown in Figure 7-6. We are unable to fully understand the structure of the blood vessels from this still image since we cannot determine whether some vessel is in front of or behind some other vessel. This problem can be solved by generating a small sequence of images showing the data rotating, although for parallel camera projections even this animation will be ambiguous. This is due to the fact that two images generated from cameras that view the data from opposite directions will be identical except for a reflection about the Y axis of the image.
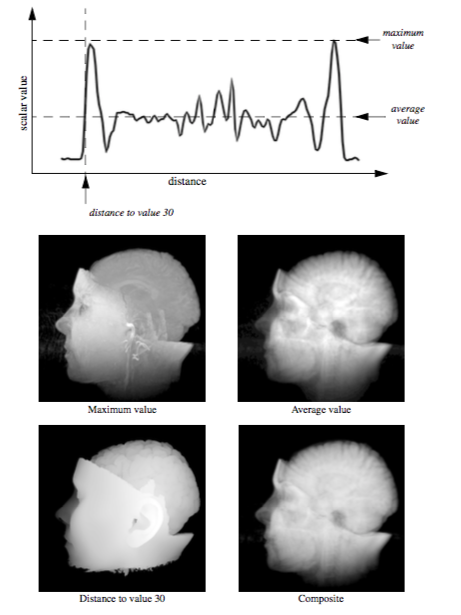
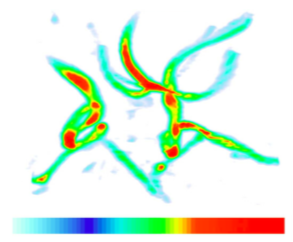
Later in this chapter, during the classification and illumination discussions, we will consider more complex ray functions. Although the colorful, shaded images produced by the new methods may contain more information, they may also be more difficult to interpret, and often easier to misinterpret, than the simple images of the previous examples. For that reason, it is beneficial to use multiple techniques to visualize your volumetric data.
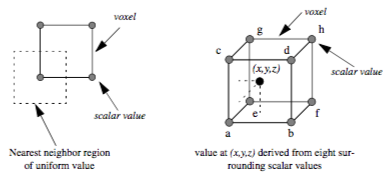
A volume is represented as a 3D image dataset where scalar values are defined at the points of the regular grid, yet in ray casting we often need to sample the volume at arbitrary locations. To do this we must define an interpolation function that can return a scalar value for any location between grid points. The simplest interpolation function, which is called zero-order, constant, or nearest neighbor interpolation, returns the value of the closest grid point. This function defines a grid of identical rectangular boxes of uniform value centered on grid points, as illustrated in 2D on the left side of Figure 7-7. In the image on the right we see an example of trilinear interpolation where the value at some location is defined by using linear interpolation based on distance along each of the three axes. In general, we refer to the region defined by eight neighboring grid points as a voxel. In the special case where a discrete algorithm is used in conjunction with nearest neighbor interpolation, we may instead refer to the constant-valued regions as voxels.
To traverse the data along a ray, we could sample the volume at uniform intervals or we could traverse a discrete representation of the ray through the volume, examining each voxel encountered, as illustrated in Figure 7-8. The selection of a method depends upon factors such as the interpolation technique, the ray function, and the desired trade-off between image accuracy and speed.
The ray is typically represented in parametric form as
where x_0,y_0,z_0) is the origin of the ray (either the camera position for perspective viewing transformations or a pixel on the view plane for parallel viewing transformations), and (a, b, c) is the normalized ray direction vector. If t1 and t2 represent the distances where the ray enters and exits the volume respectively, and delta_t indicates the step size, then we can use the following code fragment to perform uniform distance sampling:
t = t1;
v = undefined;
while ( t < t2 )
{
x = x0 + a * t;
y = y0 + b * t;
z = z0 + c * t;
v = EvaluateRayFunction( v, t );
t = t + delta_t;
}
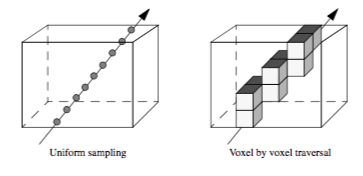
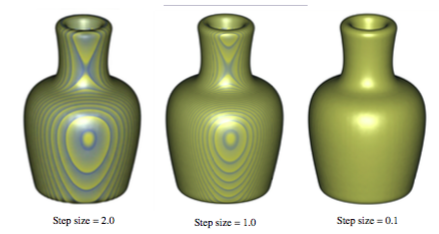
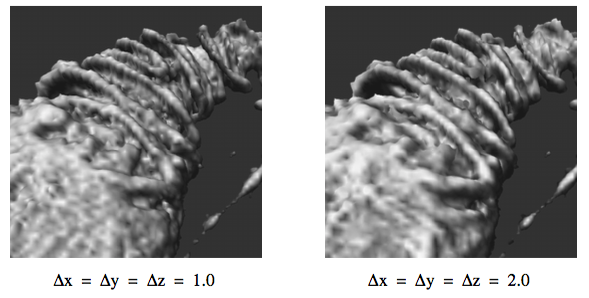
One difficulty with the uniform distance sampling method is selecting the step size. If the step size is too large, then our sampling might miss features in the data, yet if we select a small step size, we will significantly increase the amount of time required to render the image. This problem is illustrated in Figure 7-9 using a volumetric dataset with grid points that are one unit apart along the X, Y, and Z axes. The images were generated using step sizes of 2.0, 1.0, and 0.1 units, where the 0.1 step-size image took nearly 10 times as long to generate as the 1.0 step-size image, which in turn took twice as long to render as the 2.0 step-size image. A compositing method was used to generate the images, where the scalar values within the dataset transition sharply from transparent black to opaque white. If the step size is too large, a banding effect appears in the image highlighting regions of the volume equidistant from the ray origin along the viewing rays. To reduce this effect when a larger step size is desired for performance reasons, the origin of each ray can be bumped forward along the viewing direction by some small random offset, which will produce a more pleasing image by eliminating the regular pattern of the aliasing.
In some cases it may make more sense to examine each voxel along the ray rather than taking samples. For example, if we are visualizing our data using a nearest neighbor interpolation method, then we may be able to implement a more efficient algorithm using discrete ray traversal and integer arithmetic. Another reason for examining voxels may be to obtain better accuracy on certain ray functions. We can compute the exact maximum value encountered along a ray within each voxel when using trilinear interpolation by taking the first derivative of the interpolation function along the ray and solving the resulting equation to compute the extrema. Similarly, we can find the exact location along the ray where a selected value is first encountered to produce better images of isovalue surfaces within the volume.
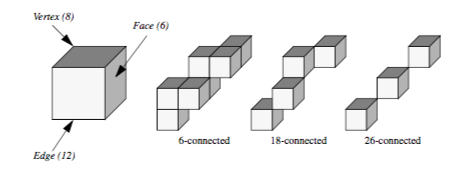
A 3D scan conversion technique, such as a modified Bresenham method, can be used to transform the continuous ray into a discrete representation. The discrete ray is an ordered sequence of voxels v_1, v_2,... v_n and can be classified as 6-connected, 18-connected, or 26-connected as shown in Figure 7-10. Each voxel contains 6 faces, 12 edges, and 8 vertices. If each pair of voxels v_i, v_{i+1} along the ray share a face then the ray is 6-connected, if they share a face or an edge the ray is 18-connected, and if they share a face, an edge, or a vertex the ray is 26-connected. Scan converting and traversing a 26-connected ray requires less time than a 6-connected ray but is more likely to miss small features in the volume dataset.
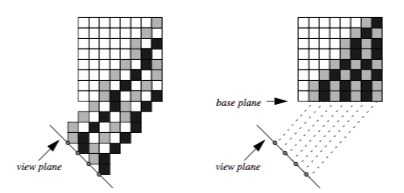
If we are using a parallel viewing transformation and our ray function can be efficiently computed using a voxel by voxel traversal method, then we can employ a templated ray casting technique [Yagel92b] with 26-connected rays to generate the image. All rays are identical in direction; therefore, we only need to scan convert once, using this "template" for every ray. When these rays are cast from pixels on the image plane, as shown in the left image of Figure 7-11, then some voxels in the dataset will not contribute to the image. If instead we cast the rays from the voxels in the base plane of the volume that is most parallel to the image plane, as shown in the right image, then the rays fit together snugly such that every voxel in the dataset is visited exactly once. The image will appear warped because it is generated from the base plane, so a final resampling step is required to project this image back onto the image plane.
7.5 Object-Order Volume Rendering¶
Object-order volume rendering methods process samples in the volume based on the organization of the voxels in the dataset and the current camera parameters. When an alpha compositing method is used, the voxels must be traversed in either a front-to-back or back-to-front order to obtain correct results. This process is analogous to sorting translucent polygons before each projection in order to ensure correct blending. When graphics hardware is employed for compositing, a back-to-front ordering is typically preferred since it is then possible to perform alpha blending without the need for alpha bit planes in the frame buffer. If a software compositing method is used, a front-to-back ordering is more common since partial image results are more visually meaningful, and can be used to avoid additional processing when a pixel reaches full opacity. Voxel ordering based on distance to the view plane is not always necessary since some volume rendering operations, such as MIP or average, can be processed in any order and still yield correct results.
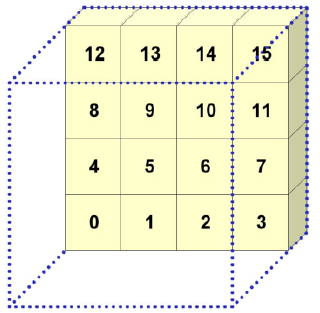
Figure 7-12 illustrates a simple object-order, back-to-front approach to projecting the voxels in a volume for an orthographic projection. Voxel traversal starts at the voxel that is furthest from the view plane and then continues progressively to closer voxels until all voxels have been visited. This is done within a triple nested loop where, from the outer to the inner loop, the planes in the volume are traversed, the rows in a plane are processed, and finally the voxels along a row are visited. Figure 7-12 shows an ordered labeling of the first seven voxels as the volume is projected. Processing voxels in this manner does not yield a strict ordering from the furthest to the closest voxel. However, it is sufficient for orthographic projections since it does ensure that the voxels that project to a single pixel are processed in the correct order.

When a voxel is processed, its projected position on the view plane is determined and an operation is performed at that pixel location using the voxel and image information. This operator is similar to the ray function used in image-order ray casting techniques. Although this approach to projecting voxels is both fast and efficient, it often yields image artifacts due to the discrete selection of the projected image pixel. For instance, as we move the camera closer to the volume in a perspective projection, neighboring voxels will project to increasingly distant pixels on the view plane, resulting in distracting "holes" in the image.
A volume rendering technique, called splatting, addresses this problem by distributing the energy of a voxel across many pixels. Splatting is an object-order volume rendering technique proposed by Westover [Westover90] and, as its name implies, it projects the energy of a voxel onto the image plane one splat, or footprint, at a time. A kernel with finite extent is placed around each data sample. The footprint is the projected contribution of this sample onto the image plane, and is computed by integrating the kernel along the viewing direction and storing the results in a 2D footprint table. Figure 7-13 illustrates the projection of a Gaussian kernel onto the image plane that may then be used as a splatting footprint. For a parallel viewing transform and a spherically symmetric kernel, the footprint of every voxel is identical except for an image space offset. Therefore, the evaluation of the footprint table and the image space extent of a sample can be performed once as a preprocessing step to volume rendering. Splatting is more difficult for perspective volume rendering since the image space extent is not identical for all samples. Accurately correcting for perspective effects in a splatting approach would make the algorithm far less efficient. However, with a small loss of accuracy we can still use the generic footprint table if we approximate the image plane extent of an ellipsoid with an ellipse.
There are several important considerations when utilizing a splatting approach for volume rendering. The type of kernel, the radius of the kernel, and the resolution of the footprint table will all impact the appearance of the final image. For example, a kernel radius that is smaller than the distance between neighboring samples may lead to gaps in the image, while a larger radius will lead to a blurry image. Also, a low resolution footprint table is faster to precompute, but a high resolution table allows us to use nearest neighbor sampling for faster rendering times without a significant loss in image accuracy.
Texture mapping as described earlier in this chapter was originally developed to provide the appearance of high surface complexity when rendering geometric surfaces. As texture mapping methods matured and found their way into standard graphics hardware, researchers began utilizing these new capabilities to perform volume rendering [Cabral94]. There are two main texture-mapped volume rendering techniques based on the two main types of texture hardware currently available. Two-dimensional texture-mapped volume rendering makes use of 2D texture mapping hardware whereas 3D texture-mapped volume rendering makes use less commonly available 3D texture mapping graphics hardware.
We can decompose texture-mapped volume rendering into two basic steps. The first is a sampling step where the data samples are extracted from the volume using some form of interpolation. Depending on the type of texture hardware available, this may be nearest neighbor, bilinear, or tri-linear interpolation and may be performed exclusively in hardware or through a combination of both software and hardware techniques. The second step is a blending step where the sampled values are combined with the current image in the frame buffer. This may be a simple maximum operator or it may be a more complex alpha compositing operator.
Texture-mapped volume renderers sample and blend a volume to produce an image by projecting a set of texture-mapped polygons that span the entire volume. In 2D texture-mapped volume rendering the dataset is decomposed into a set of orthographic slices along the axis of the volume most parallel to the viewing direction. The basic rendering algorithm consists of a loop over the orthogonal slices in a back-to-front order, where for each slice, a 2D texture is downloaded into texture memory. Each slice, which is a rectangular polygon, is projected to show the entire 2D texture. If neighboring slices are far apart relative to the image size, then it may be necessary to use a software bilinear interpolation method to extract additional slices from the volume in order to achieve a desired image accuracy. The image on the left side of Figure 7-14 illustrates the orthogonal slices that are rendered using a 2D texture mapping approach. Several example images generated using 2D texture-mapped volume rendering are shown in Figure 7-15.
The performance of this algorithm can be decomposed into the software sampling rate, the texture download rate, and the texture-mapped polygon scan conversion rate. The software sampling step is required to create the texture image, and is typically dependent on view direction due to cache locality when accessing volumetric data stored in a linear array. Some implementations minimize the software sampling cost at the expense of memory by precomputing and saving images for the three major volume orientations. The texture download rate is the rate at which this image can be transferred from main memory to texture mapping memory. The scan conversion of the polygon is usually limited by the rate at which the graphics hardware can process pixels in the image, or the pixel fill rate. For a given hardware implementation, the download time for a volume is fixed and will not change based on viewing parameters. However, reducing the relative size of the projected volume will reduce the number of samples processed by the graphics hardware that, in turn, will increase volume rendering rates at the expense of image quality.
Unlike 2D hardware, 3D texture hardware is capable of loading and interpolating between multiple slices in a volume by utilizing 3D interpolation techniques such as trilinear interpolation. If the texture memory is large enough to hold the entire volume, then the rendering algorithm is simple. The entire volume is downloaded into texture memory once as a preprocessing step. To render an image, a set of equally spaced planes along the viewing direction and parallel to the image plane is clipped against the volume. The resulting polygons, illustrated in the image on the right side of Figure 7-14, are then projected in back-to-front order with the appropriate 3D texture coordinates.
For large volumes it may not be possible to load the entire volume into 3D texture memory. The solution to this problem is to break the dataset into small enough subvolumes, or bricks, so that each brick will fit in texture memory. The bricks must then be processed in back-to-front order while computing the appropriately clipped polygon vertices inside the bricks. Special care must be taken to ensure that boundaries between bricks do not result in image artifacts.
Similar to a 2D texture mapping method, the 3D algorithm is limited by both the texture download and pixel fill rates of the machine. However, 3D texture mapping is superior to the 2D version in its ability to sample the volume, generally yielding higher quality images with fewer artifacts. Since it is capable of performing trilinear interpolation, we are able to sample at any location within the volume. For instance, a 3D texture mapping algorithm can sample along polygons representing concentric spheres rather than the more common view-aligned planes.
In theory, a 3D texture-mapped volume renderer and a ray casting volume renderer perform the same computations, have the same complexity O^{n_3}, and produce identical images. Both sample the entire volume using either nearest neighbor or trilinear interpolation, and combine the samples to form a pixel value using, for example, a maximum value or compositing function. Therefore, we can view 3D texture mapping and standard ray casting methods as functionally equivalent. The main advantage to using a texture mapping approach is the ability to utilize relatively fast graphics hardware to perform the sampling and blending operations. However, there are currently several drawbacks to using graphics hardware for volume rendering. Hardware texture-mapped volume renderings tend to have more artifacts than software ray casting techniques due to limited precision within the frame buffer for storing partial results at each pixel during blending. In addition, only a few ray functions are supported by the hardware, and advanced techniques such as shading are more difficult to achieve. However, these limitations are beginning to disappear as texture mapping hardware evolves. Through the use of extensions to the OpenGL standard, per pixel vectors can be defined allowing for hardware shaded volume texture mapping. Other extensions have allowed for maximum intensity projections, and deeper frame buffers eliminate artifacts.
7.6 Other Volume Rendering Methods¶
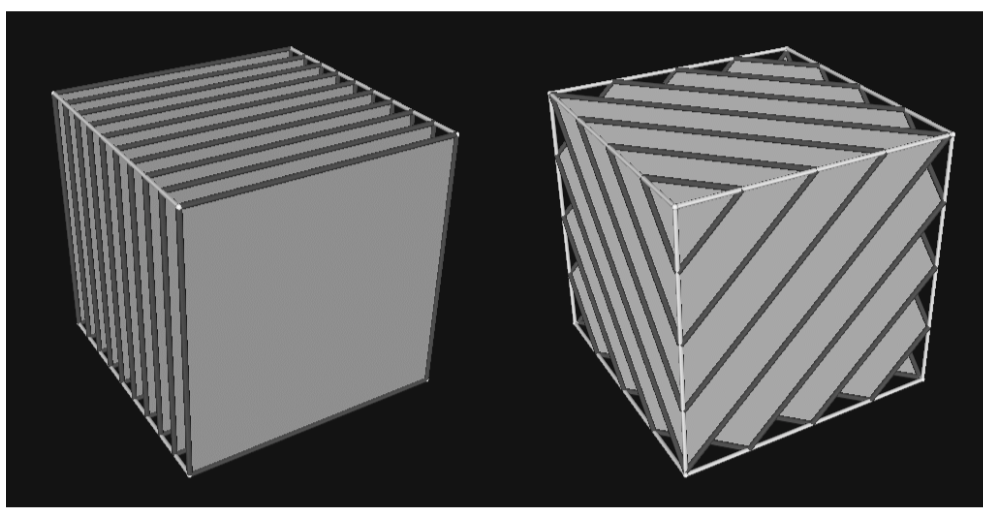
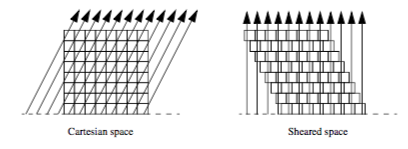
Not all volume rendering methods fall cleanly into the image-order or object-order categories. For example, the shear-warp method [Lacroute94] of volume rendering traverses both image and object space at the same time. The basic idea behind this method is similar to that of templated ray casting. If we cast rays from the base plane of the volume for an orthographic projection, then it is possible to shear the volume such that the rays become perpendicular to the base plane, as shown in Figure 7-16. Looking at the problem this way, it is clear to see that if all rays originate from the same place within the voxels on the base plane, then these rays intersect the voxels on each subsequent plane of the volume at consistent locations. Using bilinear interpolation on the 2D planes of the dataset, we can precompute one set of interpolation weights for each plane. Instead of traversing the volume by evaluating samples along each ray, an object-order traversal method can be used to visit voxels along each row in each plane in a front-to-back order through the volume. There is a one-to-one correspondence between samples in a plane of the volume and pixels on the image plane, making it possible to traverse both the samples and the pixels simultaneously. As in templated ray casting, a final resampling (warping) operation must be performed to transform the image from sheared space on the base plane to Cartesian space on the image plane.
Shear-warp volume rendering is essentially an efficient variant of ray casting. The correspondence between samples and pixels allows us to take advantage of a standard ray casting technique known as early ray termination. When we have determined that a pixel has reached full opacity during compositing, we no longer need to consider the remaining samples that project onto this pixel since they do not contribute to the final pixel value. The biggest efficiency improvement in shear-warp volume rendering comes from run-length encoding the volume. This compression method removes all empty voxels from the dataset, leaving only voxels that can potentially contribute to the image. Depending on the classification of the data, it is possible to achieve a greater than 10:1 reduction in voxels. As we step through the compressed volume, the number of voxels skipped due to run-length encoding also indicates the number of pixels to skip in the image. One drawback to this method is that it requires three copies of the compressed volume to allow for front-to-back traversal from all view directions. In addition, if we wish to use a perspective viewing transformation then we may need to traverse all three compressed copies of the volume in order to achieve the correct traversal order.
Volume rendering can also be performed using the Fourier slice projection theorem [Totsuka92] that states that if we extract a slice of the volume in the frequency domain that contains the center and is parallel to the image plane, then the 2D spectrum of that slice is equivalent to the 2D image obtained by taking line integrals through the volume from the pixels on the image plane. Therefore we can volume render the dataset by extracting the appropriate slice from the 3D Fourier volume, then computing the 2D inverse Fourier transform of this slice. This allows us to render the image in O(n^2 \log n) time as opposed to the O(n^3) complexity required by most other volume rendering algorithms.
Two problems that must be addressed when implementing a frequency domain volume renderer are the high cost of interpolation when extracting a slice from the Fourier volume, and the high memory requirements (usually two double precision floating-point values per sample) required to store the Fourier volume. Although some shading and depth cues can be provided with this method, occlusion is not possible.
7.7 Volume Classification¶
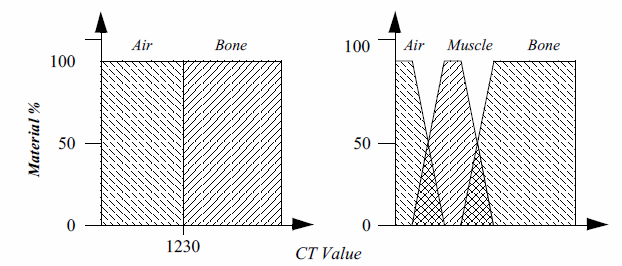
Classifying the relevant objects of interest within a dataset is a critical step in producing a volume rendered image. This information is used to determine the contribution of an object to the image as well as the object's material properties and appearance. For example, a simple binary classification of whether a data sample corresponds to bone within a CT dataset is often performed by specifying a density threshold. When the scalar value at a voxel is greater than this threshold, it is classified as bone, otherwise it is considered air. This essentially specifies an isosurface in the volume at the transition between air and bone. If we plot this operation over all possible scalar values we will get the binary step function shown on the left in Figure 7-17. In volume rendering we refer to this function as a transfer function. A transfer function is responsible for mapping the information at a voxel location into different values such as material, color, or opacity. The strength of volume rendering is that it can handle transfer functions of much greater complexity than a binary step function. This is often necessary since datasets contain multiple materials and classification methods cannot always assign a single material to a sample with 100 percent probability. Using advanced image segmentation and classification techniques, the single component volume can be processed into multiple material percentage volumes [Drebin88]. Referring back to our CT example, we can now specify a material percentage transfer function that defines a gradual transition from air to muscle, then from muscle to bone, as shown on the right in Figure 7-17.
In addition to material percentage transfer functions, we can define four independent transfer functions that map scalar values into red, green, blue, and opacity values for each material in the dataset. For simplicity, these sets of transfer functions are typically pre-processed into one function each for red, green, blue and opacity at the end of the classification phase. During rendering we must decide how to perform interpolation to compute the opacity and color at an arbitrary location in the volume. We could interpolate scalar value then evaluate the transfer functions, or we could evaluate the transfer functions at the grid points then interpolate the resulting opacities and colors. These two methods will produce different image results. It is generally considered more accurate to classify at the grid points then interpolate to obtain color and opacity; although if we interpolate then classify, the image often appears more pleasing since high frequencies may be removed by the interpolation.
Classifying a volume based on scalar value alone is often not capable of isolating an object of interest. A technique introduced by Levoy [Levoy88] adds a gradient magnitude dimension to the specification of a transfer function. With this technique we can specify an object in the volume based on a combination of scalar value and the gradient magnitude. This allows us to define an opacity transfer function that can target voxels with scalar values in a range of densities and gradients within a range of gradient magnitudes. This is useful for avoiding the selection of homogeneous regions in a volume and highlighting fast-changing regions. Figure 7-18 shows a CT scan of a human foot. The sharp changes in the volume, such as the transition from air to skin and flesh to bone, are shown. However, the homogeneous regions, such as the internal muscle, are mostly transparent.
If we are using a higher-order interpolation function such as tri-cubic interpolation then we can analytically compute the gradient vector at any location in the dataset by evaluating the first derivative of the interpolation function. Although we can use this approach for trilinear interpolation, it may produce undesirable artifacts since trilinear interpolation is not continuous in its first derivative across voxel boundaries. An alternative approach is to employ a finite differences technique to approximate the gradient vector:
where f(x,y,z) represents the scalar value at (x,y,z) location in the dataset according to the interpolation function, and g_x, g_y and g_z are the partial derivatives of this function along the x, y, and z axes respectively. The magnitude of the gradient at (x,y,z) is the length of the resulting vector (g_x, g_y, g_z). This vector can also be normalized to produce a unit normal vector. The $\Delta x, \Delta y, $ and \Delta z are critical as shown in Figure 7-19. If these values are too small, then the gradient vector field derived from Equation7-3 may contain high frequencies, yet if these values are too large we will lose small features in the dataset.
It is often the case that transfer functions based on scalar value and even gradient magnitude are not capable of fully classifying a volume. Ultrasound data is an example of particularly difficult data that does not perform well with simple segmentation techniques. While no one technique exists that is universally applicable, there exists a wide variety of techniques that produce classification information at each sample. For instance, [Kikinis96] provides techniques for classifying the human brain. In order to properly handle this information a volume renderer must access the original volume and a classification volume. The classification volume usually contains material percentages for each sample, with a set of color and opacity transfer functions for each material used to define appearance.
7.8 Volumetric Illumination¶
The volume rendered images that we have shown so far in this chapter do not include any lighting effects. Scientist sometimes prefer to visualize their volumes using these simpler methods because they fear that adding lighting effects to the image will interfere with their interpretation. For example, in a maximum intensity projection, a dark region in the image clearly indicates the lack of high opacity values in the corresponding region of the volume, while a dark feature in a shaded image may indicate either low opacity values or values with gradient directions that point away from the light source.
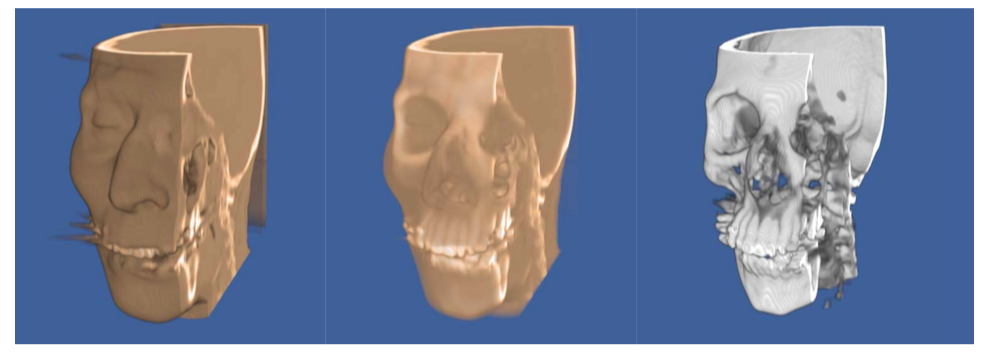
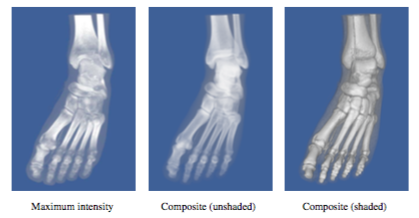
There are several advantages to lighting that can often justify the additional complexity in the image. First, consider the fact that volume rendering is a process of creating a 2D image from 3D data. The person viewing that data would like to be able to understand the 3D structure of the volume from that image. Of course, if you were to look at a photograph of a skeleton it would be easy to understand its structure from the 2D representation. The two main clues that you received from the picture are occlusion and lighting effects. If you were to view a video of the skeleton, you would receive the additional clue of motion parallax. A static image showing a maximum intensity projection does not include occlusion or lighting effects, making it difficult to understand structure. An image generated with a compositing technique does include occlusion, and the compositing ray function can be modified to include shading as well. A comparison of these three methods is shown in Figure 7-20 for a CT scan of a human foot.
To accurately capture lighting effects, we could use a transport theory illumination model [Krueger91] that describes the intensity of light I arriving at a pixel by the path integral along the ray:
If we are using camera clipping planes, then t_0 and \infty would be replaced by the distance to the near clip plane t_{near} and the distance to the far clip plane t_{far} respectively. The contribution Q(t) from each sample at a distance t along the ray is attenuated according to how much intensity is lost on the way from t to t_0 due to absorption \sigma_a(t') and scattering \sigma_{sc}(t'). The contributions at t can be defined as:
The contribution consists of the amount of light directly emitted by the sample E(t), plus the amount of light coming from all directions that is scattered by this sample back along the ray. The fraction of light arriving from the \vec{\omega'} direction that is scattered into the direction \vec{\omega} is defined by the scattering function \rho_{sc}(\vec{\omega'}\rightarrow \vec{\omega}). To compute the light arriving from all directions due to multiple bounce scattering, we must recursively compute the illumination function.
If scattering is accurately modelled, then basing the ray function on the transport theory illumination model will produce images with realistic lighting effects. Unfortunately, this illumination model is too complex to evaluate, therefore approximations are necessary for a practical implementation. One of the simplest approximations is to ignore scattering completely, yielding the following intensity equation:
We can further simplify this equation by allowing $\alpha (t) to represent both the amount of light emitted per unit length and the amount of light absorbed per unit length along the ray. The outer integral can be replaced by a summation over samples along the ray within some clipping range, while the inner integral can be approximated using an over operator:
This equation is typically expressed in its recursive form:
which is equivalent to the simple compositing method using the over operator that was described previously. Clearly in this case we have simplified the illumination model to the point that this ray function does not produce images that appear to be realistic.
If we are visualizing an isosurface within the volumetric data, then we can employ the surface illumination model described in Chapter 3 to capture ambient and diffuse lighting as well as specular highlights. There are a variety of techniques for estimating the surface normal needed to evaluate the shading equation. If the image that is produced as a result of volume rendering contains the distance from the view plane to the surface for every pixel, then we can post-process the image with a 2D gradient estimator to obtain surface normals. The gradient at some pixel x_p, y_p can be estimated with a central difference technique by:
The results are normalized to produce a unit normal vector. As with the 3D finite differences gradient estimator given in Equation7-3 care must be taken when selecting $\delta x and \delta y Typically, these values are simply the pixel spacing in x and y so that neighboring pixel values are used to estimate the gradient, although larger values can be used to smooth the image.
One problem with the 2D gradient estimation technique described above is that normals are computed from depth values that may represent disjoint regions in the volume, as shown in Figure 7-21. This may lead to a blurring of sharp features on the edges of objects. To reduce this effect, we can locate regions of continuous curvature in the depth image, then estimate the normal for a pixel using only other pixel values that fall within the same curvature region [Yagel92a]. This may require reducing our \Delta x and \Delta y values, or using an off-centered differences technique to estimate the components of the gradient. For example, the x component of the gradient could be computed with a forward difference:
or a backward difference
Although 2D gradient estimation is not as accurate as the 3D version, it is generally faster and allows for quick lighting and surface property changes without requiring us to recompute the depth image. However, if we wish to include shading effects in an image computed with a compositing technique, we need to estimate gradients at many locations within the volume for each pixel. A 3D gradient estimation technique is more suitable for this purpose. An illumination equation for compositing could be written as:
where the ambient illumination I_a, the diffuse illumination I_d, and the specular illumination I_s are computed as in surface shading using the estimated volume gradient in place of the surface normal. In this equation, \alpha(t) represents the amount of light reflected per unit length along the ray, with 1 - \alpha*(t) indicating the fraction of light transmitted per unit length.
As in classification, we have to make a decision about whether to directly compute illumination at an arbitrary location in the volume, or to compute illumination at the grid points and then interpolate. This is not a difficult decision to make on the basis of accuracy since it is clearly better to estimate the gradient at the desired location rather than interpolate from neighboring estimations. On the other hand, if we do interpolate from the grid points then we can precompute the gradients for the entire dataset once, and use this to increase rendering performance for both classification and illumination. The main problem is the amount of memory required to store the precomputed gradients. A naive implementation would store a floating-point value (typically four bytes) per component of the gradient per scalar value. For a dataset with one 256^3 one-byte scalars, this would increase the storage requirement from 16 Mbytes to 218 Mbytes.
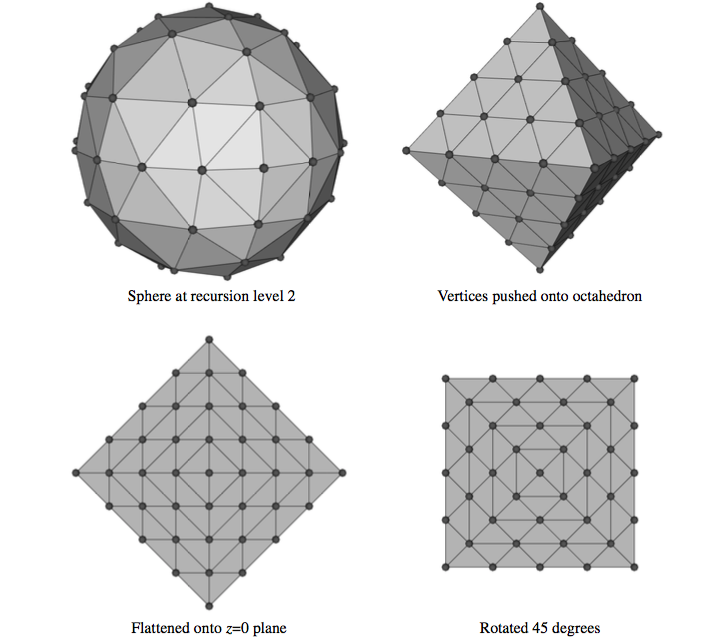
In order to reduce the storage requirements, we could quantize the precomputed gradients by using some number of bits to represent the magnitude of the vector, and some other number of bits to encode the direction of the vector. Quantization works well for storing the magnitude of the gradient, but does not provide a good distribution of directions if we simply divide the bits among the three components of the vector. A better solution is to use the uniform fractal subdivision of an octahedron into a sphere as the basis of the direction encoding, as shown in Figure 7-22. The top left image shows the results obtained after the recursive replacement of each triangle with four new triangles, with a recursion depth of two. The vector directions encoded in this representation are all directions formed by creating a ray originating at the sphere's center and passing through a vertex of the sphere. The remaining images in this figure illustrate how these directions are mapped into an index. First we push all vertices back onto the original faces of the octahedron, then we flatten this sphere onto the plane z=0. Finally, we rotate the resulting grid by 45^\circ. We label the vertices in the grid with indices starting at 0 at the top left vertex and continue across the rows then down the columns to index 40 at the lower right vertex. These indices represent only half of the encoded normals because when we flattened the octahedron, we placed two vertices on top of each other on all but the edge locations. Thus, we can use indices 41 through 81 to represent vectors with a negative z component. Vertices on the edges represent vectors with out a z component, and although we could represent them with a single index, using two keeps the indexing scheme more consistent and, therefore, easier to implement.
The simple example above requires only 82 values to encode the 66 unique vector directions. If we use an unsigned short to store the encoded direction, then we can use a recursion depth of 6 when generating the vertices. This leads to 16,642 indices representing 16,386 unique directions.
Once the gradients have been encoded for our volume, we need only compute the illumination once for each possible index and store the results in a table. Since data samples with the same encoded gradient direction may have different colors, this illumination value represents the portion of the shading equation that is independent of color. Each scalar value may have separate colors defined for ambient, diffuse, and specular illumination; therefore, the precomputed illumination is typically an array of values.
Although using a shading table leads to faster rendering times, there are some limitations to this method. Only infinite light sources can be supported accurately since positional light sources would result in different light vectors for data samples with the same gradient due to their different positions in the volume. In addition, specular highlights are only captured accurately for orthographic viewing directions where the view vector does not vary based on sample position. In practice, positional light sources are often approximated by infinite light sources, and a single view direction is used for computing specular highlights since the need for fast rendering often outweighs the need for accurate illumination.
7.9 Regions of Interest¶
One difficulty in visualizing volumetric data with the methods presented thus far is that in order to study some feature in the center of the volume we must look through other features in the dataset. For example, if we are visualizing a tomato dataset, then we will be unable to see the seeds within the tomato using a maximum intensity projection because the seeds have lower intensity than the surrounding pulp. Even using a compositing technique, it is difficult to visualize the seeds since full opacity may be obtained before reaching this area of the dataset.
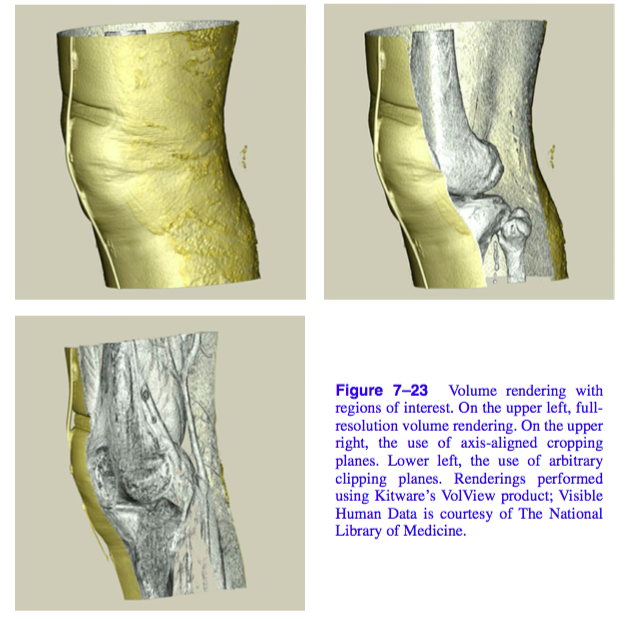
We can solve the problem of visualizing internal features by defining a region of interest within our volume, and rendering only this portion of the dataset as shown in Figure 7-23. There are many techniques for defining a region of interest. We could use the near and far clipping planes of the camera to exclude portions of the volume. Alternatively, we could use six orthographic clipping planes that would define a rectangular subvolume; we could use a set of arbitrarily oriented half-space clipping planes; or we could define the region of interest as the portion of the volume contained within some set of closed geometric objects. Another approach would be to create an auxiliary volume with binary scalar values that define a mask indicating which values in the volume should be considered during rendering.

All of these region of interest methods are fairly simple to implement using an image-order ray casting approach. As a preprocessing step to ray casting, the ray is clipped against all geometric region definitions. The ray function is then evaluated only along segments of the ray that are within the region of interest. The mask values are consulted at each sample to determine if its contribution should be included or excluded.
For object-order methods we must determine for each sample whether or not it is within the region of interest before incorporating its contribution into the image. If the underlying graphics hardware is being utilized for the object-order volume rendering as is the case with a texture mapping approach, hardware clipping planes may be available to help support regions of interest.
7.10 Intermixing Volumes and Geometry¶
Although the volume is typically the focus of the image in volume visualization, it is often helpful to add geometric objects to the scene. For example, showing the bounding box of the dataset or the position and orientation of cut planes can improve the viewer's understanding of the volumetric data. Also, it can be useful to visualize volumetric data using both geometric and volumetric methods within the same image. The left image in Figure 7-24 shows a CT scan of a human knee where a contouring method is used to extract the skin isosurface. This isosurface is rendered as triangles using standard graphics hardware. The upper-right portion of the skin is cut to reveal the bone beneath, which is rendered using a software ray casting technique with a compositing ray function. In the right image, the wave function values of an iron protein are visualized using both geometric isosurface and volume rendering techniques.
When using graphics hardware to perform volume rendering, as is the case with a texture mapping approach, intermixing opaque geometry in the scene is trivial. All opaque geometry is rendered first, then the semi-transparent texture-mapped polygons are blended in a back-to-front order into the image. If we wish to include semi-transparent geometry in the scene, then this geometry and the texture-mapped polygons must be sorted before rendering. Similar to a purely geometric scene, this may involve splitting polygons to obtain a sorted order.
If a software volume rendering approach is used, such as an object-order splatting method or an image-order ray casting method, opaque geometry can be incorporated into the image by rendering the geometry, capturing the results stored in the hardware depth buffer, and then using these results during the volume rendering phase. For ray casting, we would simply convert the depth value for a pixel into a distance along the view ray and use this to bound the segment of the ray that we consider during volume rendering. The final color computed for a pixel during volume rendering is then blended with the color produced by geometric rendering using the over operator. In an object-order method, we must consider the depth of every sample and compare this to the value stored in the depth buffer at each pixel within the image extent of this sample. We accumulate this sample's contribution to the volume rendered image at each pixel only if the sample is in front of the geometry for that pixel. Finally, the volume rendered image is blended over the geometric image.
7.11 Efficient Volume Rendering¶
Rendering a volumetric dataset is a computationally intensive task. If n is the size of the volume on all three dimensions and we visit every voxel once during a projection, the complexity of volume rendering is O(n^3). Even a highly optimized software algorithm will have great difficulty projecting a moderately sized volume of or 512 \times 512 \times 512 approximately 134 million voxels at interactive rates. If every voxel in the volume contributes in some way to the final image and we are unwilling to compromise image quality, our options for efficiency improvements are limited. However, it has been observed that many volumetric datasets contain large regions of empty or uninteresting data that are assigned opacity values of during 0 classification. In addition, those areas that contain interesting data may be occupied by coherent or nearly homogeneous regions. There have been many techniques developed that take advantage of these observations.
Space leaping refers to a general class of efficiency improvement techniques that attempt to avoid processing regions of a volume that will not contribute to the final image. One technique often used is to build an octree data structure which hierarchically contains all of the important regions in the volume. The root node of the octree contains the entire volume and has eight child nodes, each of which represents 1/8 of the volume. These eight subregions are created by dividing the volume in half along the x, y, and z axes. This subdivision continues recursively until a node in the octree represents a homogeneous region of the volume. With an object-order rendering technique, only the nonempty leaf nodes of the octree would be traversed during rendering thereby avoiding all empty regions while efficiently processing all contributing homogeneous regions. Similarly, an image-order ray casting technique would cast rays through the leaf nodes, with the regular structure of the octree allowing us to quickly step over empty nodes.
A hybrid space leaping technique [Sobierajski95] makes use of graphics hardware to skip some of the empty regions of the volume during software ray casting. First, a polygonal representation is created that completely contains or encloses all important regions in the volume. This polygonal representation is then projected twice -- first using the usual less than operator on the depth buffer and the second time using a greater than operator on the depth buffer. This produces two depth images that contain the closest and farthest distance to relevant data for every pixel in the image. These distances are then used to clip the rays during ray casting.
An alternate space-leaping technique for ray casting involves the use of an auxiliary distance volume [Zuiderveld92], with each value indicating the closest distance to a non-transparent sample in the dataset. These distance values are used to take larger steps in empty regions of the volume while ensuring that we do not step over any non-transparent features in the volume. Unfortunately, the distance volume is computationally expensive to compute accurately, requires additional storage, and must be recomputed every time the classification of the volume is modified.
One difficulty with these space-leaping techniques is that they are highly data dependent. On a largely empty volume with a small amount of coherent data we can speed up volume rendering by a substantial amount. However, when a dataset is encountered that is entirely made up of high-frequency information such as a typical ultrasound dataset, these techniques break down and will usually cause rendering times to increase rather than decrease.
7.12 Interactive Volume Rendering¶
Generating a volume rendered image may take anywhere from a fraction of a second to tens of minutes depending on a variety of factors including the hardware platform, image size, data size, and rendering technique. If we are generating the image for the purpose of medical diagnostics we clearly would like to produce a high quality image. On the other hand, if the image is produced during an interactive session then it may be more important to achieve a desired rendering update rate. Therefore, it is clear that we need to be able to tradevoff quality for speed as necessary based on application. As opposed to our discussion on efficiency improvements, the techniques described here do not preserve image quality. Instead, they allow a controlled degradation in quality in order to achieve speed.
Since the time required for image-order ray casting depends mostly on the size of the image in pixels and the number of samples taken along the ray, we can adjust these two values to achieve a desired update rate. The full-size image can be generated from the reduced resolution image using either a nearest neighbor or bilinear interpolation method. If bilinear interpolation is used, the number of rays cast can often be reduced by a factor of two along each image dimension during interaction, resulting in a four-times speed-up, without a noticeable decrease in image quality. Further speed-ups can be achieved with larger reductions, but at the cost of blurry, less detailed images.
We can implement a progressive refinement method for ray casting if we do not reduce the number of samples taken along each ray. During interaction we can compute only every ray n^{th} along each image dimension and use interpolation to fill in the remaining pixels. When the user stops interacting with the scene the interpolated pixels are progressively filled in with their actual values.
There are several object-order techniques available for achieving interactive rendering rates at the expense of image quality. If a splatting algorithm is used, then the rendering speed is dependent on the number of voxels in the dataset. Reduced resolution versions of the data can be precomputed, and a level of resolution can be selected during interaction based on the desired frame rate. If we use a splatting method based on an octree representation, then we can include an approximate scalar value and an error value in each parent node where the error value indicates how much the scalar values in the child nodes deviate from the approximate value in the parent node. Hierarchical splatting [Laur91] can be performed by descending the octree only until a node with less than a given error tolerance is encountered. The contribution of this region of the volume on the image can be approximated by rendering geometric primitives for the splat [Shirley90], [Wilhelms91]. Increasing the allowed error will decrease the time required to render the data by allowing larger regions to be approximated at a higher level in the octree.
When using a texture mapping approach for volume rendering, faster rendering speeds can be achieved by reducing the number of texture-mapped polygons used to represent the volume. This is essentially equivalent to reducing the number of samples taken along the ray in an image-order ray casting method. Also, if texture download rates are a bottleneck, then a reduced resolution version of the volume can be loaded into texture memory for interaction. This is similar to reducing both the number of rays cast and the number of samples taken along a ray in an image-order method.
7.13 Volume Rendering Future¶
In the past two decades, volume rendering has evolved from a research topic with algorithms that required many minutes to generate an image on a high-end workstation to an area of active development with commercial software available for home computers. Yet as the demand for volume rendering increases, so do the challenges. The number of voxels in a typical dataset is growing, both due to advances in acquisition hardware and increased popularity of volume rendering in areas such as simulation and volume graphics [Kaufman93]. New methods are needed in order to satisfy the conflicting needs of high quality images and interactivity on these large datasets. In addition, time dependent datasets that contain volumetric data sampled at discrete time intervals present new challenges for interpolation, image accuracy, and interactivity while providing new opportunities in classification and interpolation methods.
Most of the volume rendering discussion in this chapter focused on regular volumetric datasets. Although it is clearly possible to extend most ray casting and object-order methods to visualize rectilinear grid, structured grid, and even irregular data, in practice it is difficult to provide both high quality images and interactivity with these methods. Rendering techniques for these data types continues to be an area of active research in volume visualization [Cignoni96], [Silva96], [Wilhelms96].
7.14 Stereo Rendering¶
In our practice of computer graphics so far, we have used a number of techniques to simulate 3D graphics on a 2D display device. These techniques include the use of perspective and scale, shading to confer depth, and motion/animation to see all sides of an object. However, one of the most effective techniques to simulate 3D viewing is binocular parallax.
Binocular parallax is a result of viewing 3D objects with our two eyes. Since each eye sees a slightly different picture, our mind interprets these differences to determine the depth of objects in our view. There have been a number of "3D" movies produced that take advantage of our binocular parallax. Typically, these involve wearing a set of special glasses while watching the movie.
This effect can be valuable in our efforts to visualize complex datasets and CAD models. The additional depth cues provided by stereo viewing aid us in determining the relative positions of scene geometry as well as forming a mental image of the scene. There are several different methods for introducing binocular parallax into renderings. We will refer to the overall process as stereo rendering, since at some point in the process a stereo pair of images is involved.
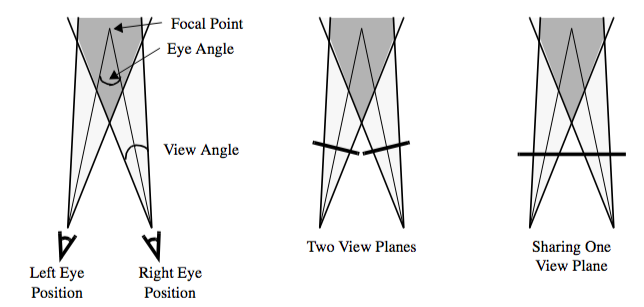
To generate correct left and right eye images, we need information beyond the camera parameters that we introduced in Chapter 3. The first piece of information we need is the separation distance between the eyes. The amount of parallax generated can be controlled by adjusting this distance. We also need to know if the resulting images will be viewed on one or two displays. For systems that use two displays (and hence two view planes), the parallax can be correctly produced by performing camera azimuths to reach the left and right eye positions. Head mounted displays and booms are examples of two display systems. Unfortunately, this doesn't work as well for systems that have only one view plane. If you try to display both the left and right views on a single display, they are forced to share the same view plane as in Figure 7-25. Our earlier camera model assumed that the view plane was perpendicular to the direction of projection. To handle this non-perpendicular case, we must translate and shear the camera's viewing frustum. Hodges provides some of the details of this operation as well as a good overview on stereo rendering [Hodges92].
Now let's look at some of the different methods for presenting stereoscopic images to the user. Most methods are based on one of two main categories: time multiplexed and time parallel techniques. Time multiplexed methods work by alternating between the left and right eye images. Time parallel methods display both images at once in combination with a process to extract left and right eye views. Some methods can be implemented as either a time multiplexed or a time parallel technique.
Time multiplexed techniques are most commonly found in single display systems, since they rely on alternating images. Typically this is combined with a method for also alternating which eye views the image. One cost-effective time multiplexed technique takes advantage of existing television standards such as NTSC and PAL. Both of these standards use interlacing, which means that first the even lines are drawn on the screen and then the odd. By rendering the left eye image to the even lines of the screen and the right eye image to the odd, we can generate a stereo video stream that is suitable for display on a standard television. When this is viewed with both eyes, it appears as one image that keeps jumping from left to right. A special set of glasses must be worn so that when the left eye image is being displayed, the user's left eye can see and similarly for the right eye. The glasses are designed so that each lens consists of a liquid crystal shutter that can either be transparent or opaque, depending on what voltage is applied to it. By shuttering the glasses at the same rate as the television is interlacing, we can assure that the correct eye is viewing the correct image.
There are a couple of disadvantages to this system. The resolutions of NTSC and PAL are both low compared to a computer monitor. The refresh rate of NTSC (60 Hz) and PAL (50 Hz) produces a fair amount of flicker, especially when you consider that each eye is updated at half this rate. Also, this method requires viewing your images on a television, not the monitor connected to your computer.
To overcome these difficulties, some computer manufacturers offer stereo ready graphics cards. These systems use liquid crystal shuttered glasses to directly view the computer monitor. To obtain the alternating stereo images, the left eye image is rendered to the top half of the screen and the right eye image to the bottom. Then the graphics card enters a special stereo mode where it doubles the refresh rate of the monitor. So a monitor that initially displays both images at 60Hz begins to alternate between the left and right eye at a rate of 120Hz. This results in each eye getting updated at 60Hz, with its original horizontal resolution and half of its original vertical resolution. For this process to work, your application must take up the entire screen while rendering.
Some more recent graphics cards have a left image buffer and a right image buffer for stereo rendering. While this requires either more memory or a lower resolution, it does provide for stereo rendering without having to take over the entire screen. For such a card, double buffering combined with stereo rendering results in quad buffering, which can result in a large number of bits per pixel. For example: 24 bits for an RGB color, another 24 bits for the back buffer's color, plus 24 bits for the z-buffer results in 72 bits per pixel. Now double that for the two different views and you have 144 bits per pixel or 18 megabytes for a 1K by 1K display.
Time parallel techniques display both images at the same time. Head-mounted displays and booms have two separate screens, one for each eye. To generate the two video streams requires either two graphics cards or one that can generate two separate outputs. The rendering process then involves just rendering each eye to the correct graphics card or output. Currently, the biggest disadvantage to this approach is the cost of the hardware required.
In contrast, SIRDS (Single Image Random Dot Stereograms) require no special hardware. Both views are displayed in a single image, as in Figure 7-26. To view such an image the user must focus either in front of, or behind, the image. When the user's focal point is correct, the two triangular cutouts in the top of the image will appear as one and the image should appear focused. This works because dot patterns repeat at certain intervals. Here, only the depth information is present in the resulting image. This is incorporated by changing the interval between patterns just as our ocular disparity changes with depth.
The next two techniques for stereo rendering can be implemented using either the time parallel or time multiplexed methods. The distinction is slightly blurred because most of the time parallel methods can be multiplexed, though typically there is no advantage to it. Both of these methods have been used by the movie industry to produce "3D" movies. The first is commonly called red-blue (or red-green or red-cyan) stereo and requires the user to wear a pair of glasses that filter entering light. The left eye can only see the image through a red filter, the right through a blue filter. The rendering process typically involves generating images for the two views, converting their RGB values into intensity, and then creating a resulting image. This image's red values are taken from the left eye image intensities. Likewise the blue values (a mixture of blue and green) are taken from the right eye image intensities. The resulting image has none of the original hue or saturation, but it does contain both original images' intensities. (An additional note: red-green methods are also used because the human eye is more sensitive to green than blue.) The benefits of this technique are that the resulting images can be displayed on a monitor, paper, or film, and all one needs to view them is an inexpensive pair of glasses.

The second technique is similar to the first but it preserves all the color information from the original images. It separates the different views by using polarized light. Normally, the light we see has a mixture of polarization angles, but there are lenses that can filter out a subset of these angles. If we project a color image through a vertical polarizing filter, and then view it through another vertical filter, we will see the original image, just slightly dimmer because we've filtered out all the horizontally polarized light. If we place a horizontal filter and a vertical filter together, all the light is blocked. Polarized stereo rendering typically projects one eye's image through a vertical filter and the other through a horizontal filter. The user wears a pair of glasses containing a vertical filter over one eye and a horizontal filter over the other. This way each eye views the correct image.
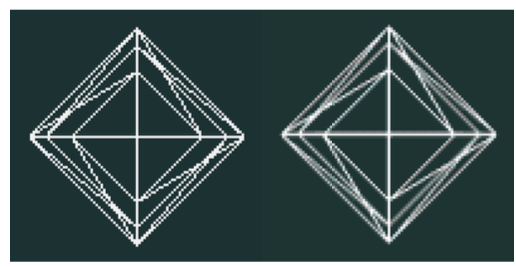
All the methods we have discussed for stereo rendering have their advantages and disadvantages, typically revolving around cost and image quality. At the end of this chapter we will look at an example program that renders stereo images using the red-blue technique.
7.15 Aliasing¶
At one point or another most computer users have run into aliasing problems. This "stair-stepping" occurs because we represent continuous surface geometry with discrete pixels. In computer graphics the most common aliasing problem is jagged edges when rendering lines or surface boundaries, as in Figure 7-27.
The aliasing problem stems from the rasterization process as the graphics system converts primitives, such as line segments, into pixels on the screen. For example, the quickest way to rasterize a line is to use an all or nothing strategy. If the line passes through the pixel, then the pixel is set to the line's color; otherwise, it is not altered. As can be seen in Figure 7-28, this results in the stair-stepped appearance.
There are several techniques for handling aliasing problems, and they are collectively known as anti-aliasing techniques. One approach to anti-aliasing is to change how the graphics system rasterizes primitives. Instead of rasterizing a line using an all or nothing approach, we look at how much of the pixel the line occupies. The resulting color for that pixel is a mixture of its original color and the line's color. The ratio of these two colors is determined by the line's occupancy. This works especially well when working primarily with wireframe models. A similar approach breaks each pixel down into smaller sub-pixels. Primitives are rendered using an all or nothing strategy, but at sub-pixel resolutions. Then the sub-pixels are averaged to determine the resulting pixel's color. This tends to require much more memory.
A good result can be obtained by breaking each pixel into 10 sub-pixels, which requires about 10 times the memory and rendering time. If you don't have access to hardware sub-pixel rendering, you can approximate it by rendering a large image and then scaling it down. Using a program such as pnmscale, which does bilinear interpolation, you can take a 1000 by 1000 pixel image and scale it down to a 500 by 500 anti-aliased image. If you have a graphics library that can render into memory instead of the screen, large images such as 6000 by 6000 pixels can be scaled down into high quality results, still at high resolutions such as 2000 by 2000. This may seem like overkill, but on a standard 600dpi color printer this would result in a picture just over three inches on a side.
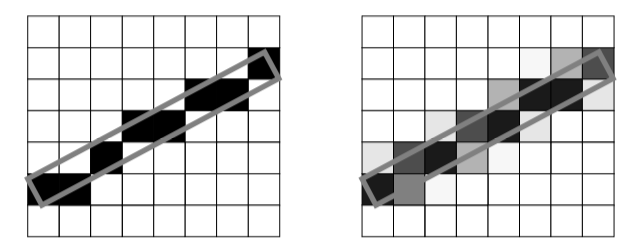
The last method of anti-aliasing we will look at uses an accumulation buffer to average a few possibly aliased images together to produce one anti-aliased result. An accumulation buffer is just a segment of memory that is set aside for performing image operations and storage. The following fragment of C++ code illustrates this process.
for (imageNum = 0; imageNum < imageTotal; imageNum++)
{
// Jitter the camera and focal point by less than one pixel
// Render an image
// add the image to the accumulation buffer
}
// Divide the accumulation buffer by imageTotal
// Display the resulting anti-aliased image
Instead of using one image with eight sub-pixels per pixel, we can use eight images without sub-pixels. The anti-aliasing is achieved by slightly translating the camera's position and focal point between each image. The amount of translation should be within one pixel of magnitude and perpendicular to the direction of projection. Of course, the camera's position is specified in world coordinates not pixels, but Equation7-13 will do the trick. We calculate the new camera position and focal point (i.e., p~new~ and f~new~) from the offset to avoid difficulties surrounding the transformation matrix at the camera's position.
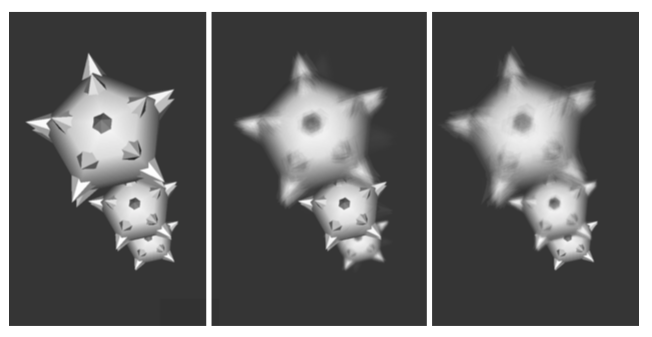
In this equation is O_p the offset in pixel coordinates, O_w is the offset in world coordinates, f camera focal point, p is the camera position, and the transformation matrices M_{WD} and $M_(DW} transform from world coordinates to display coordinates and from display coordinates to world coordinates, respectively.
7.16 Camera Tricks¶
In the previous section we saw how to combine an accumulation buffer and small camera translations to produce an anti-aliased image. In this section we will cover a few other camera techniques of interest. You may have noticed that with computer generated images all actors are in focus. With a real camera you have to set the focal depth to match the distance of the object you are photographing. Anything that is closer or farther than your focal depth will appear out of focus. This is because a real camera has a lens that lets light pass through a finite area. The camera model we have introduced has a point lens, where all the light travels through at exactly the same point. (See Figure 7-29 for a comparison.)
We can simulate a finite camera lens by rendering many images, each with a slightly different camera position but the same focal point. Then we accumulate these images and take the average. The resulting image simulates a camera lens with focal depth. The different camera positions are determined by selecting random points from the lens you are trying to simulate. Larger diameter lenses will produce more distortion and vice versa. Increasing the number of random points will improve the precision of your result. Typically 10 to 30 samples is desirable. The images in Figure 7-29 were created using 30 sample points.
Another difference between a real camera and a computer camera is in the shutter speed. Our model generates an image for a single moment in time; in contrast, a photograph captures what the camera views while its shutter is open. Fast moving objects appear blurred because of changes in their position during the small time that the shutter is open. This effect, known as motion blur, can also be simulated with our camera model ( Figure 7-30 ). Instead of rendering one image and displaying it, we render a few sub-frames that are accumulated, averaged, and finally displayed. This is similar to the anti-aliasing and focal depth techniques that we just discussed. In both of those techniques, the camera is jittered while the actors remain fixed in time. To implement motion blur we don't jitter the camera; we increment the scene's time between each sub-frame. Moving objects or camera movements will result in differences between each sub-frame. The resulting image approximates the effects of photographing moving objects over a finite time.

7.17 Mouse-Based Interaction¶
There's no doubt that being able to interactively view an object aids in understanding and recognizing its important features. Using a pointing device (e.g., a mouse or trackball) is certainly the most common method for controlling such movements. The software that accompanies this book contains the vtkRenderWindowInteractor object that translates mouse and keyboard events into modifications to the camera and actors. For example, while the user holds the left mouse button down, the vtkRenderWindowInteractor rotates the camera towards the current pointer position. The farther the pointer is from the center of the window, the faster the camera rotates.
Most of these interactions are straightforward, but there are a few issues associated with rotations. When rotating around an object, one must decide what to do with the view-up vector. We can keep it perpendicular to the direction of projection as we rotate, or we can leave it unchanged. This results in two different types of rotations. If we keep our view-up vector orthogonal to the direction of projection, we will rotate all around the object much like a plane flying around the globe. This is shown in the left half of Figure 7-31. If we leave the view-up vector unchanged, our plane will start flying backwards at the north and south poles, as shown in the right half of Figure 7-31.
The advantage of a constant view-up vector is that some objects have a natural sense of up and down (e.g., terrain). Elevation and azimuth operations remain consistent as we move around the object. On the other hand, there are singular points where the view-up vector and direction of projection become parallel. In these cases the camera viewing transformation matrix is undefined. Then we have to modify the view-up vector or use the perpendicular view-up / direction of projection method to handle this situation. If the data you are working with has a well-defined up and down, then it probably makes sense to leave the view-up constant during rotations; otherwise, it makes sense to keep it orthogonal to the direction of projection.
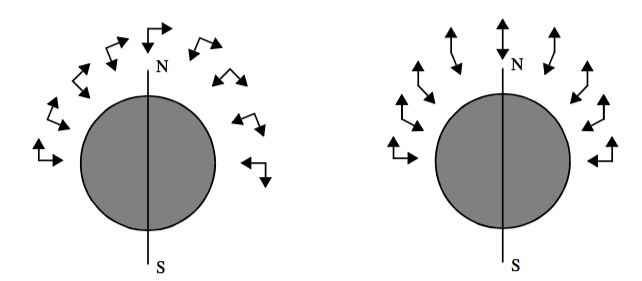
7.18 3D Widgets and User Interaction¶
Chapter 3 provided an introduction to interaction techniques for graphics (see "RenderWindowInteractor"). In the context of visualization, interaction is an essential feature of systems that provide methods for data exploration and query. The classes vtkRenderWindowInteractor and vtkInteractorStyle are core constructs used in VTK to capture windowing-system specific events in the render window, translate them into VTK events, and then take action as appropriate to that event invocation. In Chapter 3 we saw how these classes could be used to manipulate the camera and actors to interactively produce a desired view. This functionality, however, is relatively limited in its ability to interact with data. For example, users often wish to interactively control the positioning of streamline starting points, control the orientation of a clipping plane, or transform an actor. While using interpreted languages (see "Interpreted Code") can go a long way to provide this interaction, in some situations the ability to see what you are doing when placing objects is essential. Therefore, it is apparent that a variety of user interaction techniques is required by the visualization system if it is to successfully support real-world applications.
3D widgets are a logical extension of the pervasive 2D widgets found on most computer systems, providing interactive capabilities similar to their 2D counterparts except that they function in the richer 3D space. 3D widgets are capable of providing the variety of user interaction techniques required by a visualization system. Unlike 2D widgets, however, 3D widgets are relatively new technology, and because their application is in the context of a richer space, there is no consensus as to what widgets might constitute a complete set of functionality. Several popular 3D widget sets, and the University of Utah's SCIRUN 3D widgets [Purciful95], have distinctly different components in their widget toolbox. The widget sets vary according to the perceived purpose of the graphical environment in which they exist for example Open Inventor [Wernecke94], the Brown University 3D Widgets Library [Zeleznik93],
3D widgets are a recent addition (see Figure 7-32 ) to VTK. In principal, the core functionality is simple: events captured by the vtkRenderWindow are in turn translated into VTK events. Observers which have registered themselves with the vtkRenderWindow receive these VTK events, take the appropriate action, and then may either pass the event along to the next observer in the list, or abort further processing of the event. (Note: observers can be prioritized according to the order in which they wish to receive events.)
It is the implementation of 3D widgets, that is, what they can do with the events, that makes them so powerful. As Figure 7-32 shows, widgets typically provide a representation in the scene that can be selected and manipulated. For example, a vtkLineWidget can be used to position a rake of streamline seed points and represents itself with a thick line (tube) and two spherical end points. Widgets also may directly manipulate an underlying class---the vtkScalarBarWidget enables the user to interactively size, orient (horizontal or vertical), and position a vtkScalarBar. Widgets also provide additional functionality such as managing an internal implicit function or transformation matrix (e.g., vtkBoxWidget). The following is a list of widgets currently found in VTK and a brief description of their capabilities.
-
vtkScalarBarWidget --- manage a vtkScalarBar including positioning, scaling, and orienting it.
-
vtkPointWidget --- position a point x-y-z location in 3D space. The widget produces a polygonal output.
-
vtkLineWidget --- place a straight line with a specified subdivision resolution. The widget produces a polygonal output.
-
vtkPlaneWidget --- orient and position a finite plane. The plane resolution is variable and the widget produces an implicit function and a polygonal output.
-
vtkImplicitPlaneWidget --- orient and position an unbounded plane. The widget produces an implicit function and a polygonal output. The polygonal output is created by clipping the plane with a bounding box.
-
vtkBoxWidget --- orient and position a bounding box. The widget produces an implicit function and a transformation matrix.
-
vtkImagePlaneWidget --- manipulate three orthogonal planes within a 3D volumetric data set. Probing of the planes to obtain data position, pixel value, and window-level is possible.
-
vtkSphereWidget --- manipulate a sphere of variable resolution. The widget produces an implicit function, a transformation matrix, and enables the control of focal point and position to support such classes as vtkCamera and vtkLight.
-
vtkSplineWidget --- manipulate an interpolating 3D spline. The widget produces a polygonal data represented by a series of line segments of specified resolution. The widget also directly manages underlying splines for each of the x-y-z coordinate values.
The key to widget design is careful implementation of intuitive, simple user interaction techniques. For example, the end points on the vtkLineWidget (represented as small spheres) can be selected and dragged to a new position. The vtkLineWidget supports the modifier "Shift" key to lock motion of the end points along the coordinate x-y-z axes. The initial direction of motion is used to determine which of the axes the user is moving the end point along. Such attention to detail is essential to successful widget design and will continue to change as the technology evolves in the future.

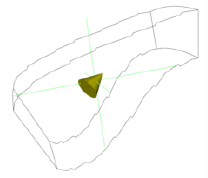
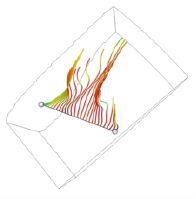
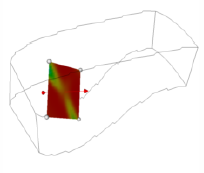
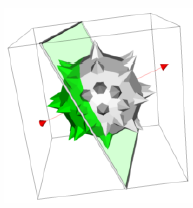
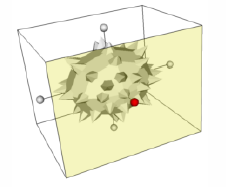
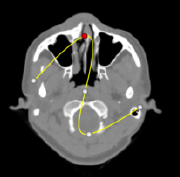
7.19 Putting It All Together¶
This chapter has covered a wide variety of topics. In this section we demonstrate applications of each topic to some simple problems.
Texture Mapping¶
Figure 7-33 shows the complete source code for a simple texture mapping example. You will notice that most of the code is similar to what we used in the preceding examples. The key step here is the creation of a vtkTexture object. This object interfaces between its data input and the texture mapping functions of the graphics library. The vtkTexture instance is associated with an actor. More than one texture instance may be shared between multiple actors. For texture mapping to function properly, texture coordinates must be defined by the actor's modeller.
One interesting note regarding the vtkTexture object. Instances of this class are mappers that have an Input instance variable that is updated during each render. The input type is a vtkImageData dataset type. Thus, a visualization pipeline can be constructed to read, process, and/or generate the texture map. This includes using the object vtkRendererSource , which converts the renderer's image into an image data dataset. The input texture map can be either 2D (a pixmap) or 3D (a volume).
A few words of warning when using textures. Some renderers only support 2D texture, or may not support alpha textures. Also, many rendering systems require that each dimension of the image dataset is an exact power of two. In VTK, non-power of two textures are automatically converted to power of two at the expense of extra computation.
Volume Rendering¶
This example focuses on volume rendering. The source code shown in example Figure 7-34 begins by creating the usual objects. Then we use a vtkStructuredPointsReader to read in a volume dataset for a high potential iron protein. We create a vtkPiecewiseFunction object to map the scalar values in the volume dataset to opacity, and a vtkColorTransferFunction object to map the scalar values to color. These two transfer functions are referenced from the vtkVolumeProperty object. In addition, we use the ShadeOn() method of vtkVolumeProperty to enable shading for this volume, and the SetInterpolationTypeToLinear() method to request trilinear interpolation. Since we are using a ray casting approach, we need to create a ray function. In this example we use a vtkVolumeRayCastCompositeFunction object for this purpose. The output of the reader is given to the vtkVolumeRayCastMapper as the scalar input, and the SetVolumeRayCastFunction() method is used to assign the ray function. The vtkVolume object is quite similar to a vtkActor, and the SetVolumeMapper() and SetVolumeProperty() methods are used just like the SetMapper() and SetProperty() methods of vtkActor. Finally, we add this volume to the renderer, adjust the camera, set the desired image update rate and start the interactor.
To produce a maximum intensity projection in Figure 7-34, we would simply change the type of the ray function to a vtkVolumeRayCastMIPFunction. We could also produce a surface image using a vtkVolumeRayCastIsosurfaceFunction where the IsoValue instance variable would be set to define the surface.
vtkBMPReader bmpReader
bmpReader SetFileName "$VTK_DATA_ROOT/Data/masonry.bmp"
vtkTexture atext
atext SetInputConnection [bmpReader GetOutputPort]
atext InterpolateOn
vtkPlaneSource plane
vtkPolyDataMapper planeMapper
planeMapper SetInputConnection [plane GetOutputPort]
vtkActor planeActor
planeActor SetMapper planeMapper
planeActor SetTexture atext
vtkRenderer ren1
vtkRenderWindow renWin
renWin AddRenderer ren1
vtkRenderWindowInteractor iren
iren SetRenderWindow renWin
# Add the actors to the renderer ]
ren1 AddActor planeActor

Red-Blue Stereo¶
In our first example, we will be looking at using red-blue stereo rendering. We start off with the example shown in Figure 7-35, which renders something akin to a mace. Then, in Figure 7-35 we add in red-blue stereo rendering by adding two lines near the bottom that invoke the StereoRenderOn() and SetStereoType() methods. Once these two methods have been invoked, further rendering will be done in stereo. The picture in the upper right corner displays a grayscale version of the resulting image.
Motion Blur¶
In our second example, we show how to simulate motion blur using the Visualization Toolkit. As shown in Figure 7-36, we begin with our previous example. We then remove the two lines controlling stereo rendering and add a few lines to create another mace. We position the first mace in the top of the rendering window and the second mace at the bottom. We then use the SetSubFrames() method to start performing subframe accumulation. Here, we will perform 21 renders to produce the final image. For motion blur to be noticeable, something must be moving, so we set up a loop to rotate the bottom mace by two degrees between each subframe. Over the 21 sub frames it will rotate 40 degrees from its initial position. It is important to remember that the resulting image is not displayed until the required number of sub frames have been rendered.
# Create the standard renderer, render window and interactor
vtkRenderer ren1
vtkRenderWindow renWin
renWin AddRenderer ren1
vtkRenderWindowInteractor iren
iren SetRenderWindow renWin
# Create the reader for the data
vtkStructuredPointsReader reader
reader SetFileName "$VTK_DATA_ROOT/Data/ironProt.vtk"
# Create transfer mapping scalar value to opacity
vtkPiecewiseFunction opacityTransferFunction
opacityTransferFunction AddPoint 20 0.0
opacityTransferFunction AddPoint 255 0.2
# Create transfer mapping scalar value to color
vtkColorTransferFunction colorTransferFunction
colorTransferFunction AddRGBPoint 0.0 0.0 0.0 0.0
colorTransferFunction AddRGBPoint 64.0 1.0 0.0 0.0
colorTransferFunction AddRGBPoint 128.0 0.0 0.0 1.0
colorTransferFunction AddRGBPoint 192.0 0.0 1.0 0.0
colorTransferFunction AddRGBPoint 255.0 0.0 0.2 0.0
# The property describes how the data will look
vtkVolumeProperty volumeProperty
volumeProperty SetColor colorTransferFunction
volumeProperty SetScalarOpacity opacityTransferFunction
volumeProperty ShadeOn
volumeProperty SetInterpolationTypeToLinear
# The mapper / ray cast function know how to render the data
vtkVolumeRayCastCompositeFunction compositeFunction
vtkVolumeRayCastMapper volumeMapper
volumeMapper SetVolumeRayCastFunction compositeFunction
volumeMapper SetInputConnection [reader GetOutputPort]
# Set the mapper and the property and
vtkVolume volume
volume SetMapper volumeMapper
volume SetProperty volumeProperty
ren1 AddVolume volume
renWin Render

vtkRenderer *ren1 = vtkRenderer::New();
vtkRenderWindow *renWin =
vtkRenderWindow::New();
renWin->AddRenderer(ren1);
vtkRenderWindowInteractor *iren =
vtkRenderWindowInteractor::New();
iren->SetRenderWindow(renWin);
// create the pipline, ball and spikes
vtkSphereSource *sphere =
vtkSphereSource::New();
sphere->SetThetaResolution(7);
sphere->SetPhiResolution(7);
vtkPolyDataMapper *sphereMapper = vtkPolyDataMapper::New();
sphereMapper->SetInputConnection(sphere->GetOutputPort());
vtkActor*sphereActor = vtkActor::New();
sphereActor->SetMapper(sphereMapper);
vtkConeSource *cone = vtkConeSource::New();
cone->SetResolution(5);
vtkGlyph3D *glyph = vtkGlyph3D::New();
glyph->SetInputConnection(sphere->GetOutputPort());
glyph->SetSourceConnection(cone->GetOutputPort());
glyph->SetVectorModeToUseNormal();
glyph->SetScaleModeToScaleByVector(); glyph->SetScaleFactor(0.25);
vtkPolyDataMapper *spikeMapper = vtkPolyDataMapper::New();
spikeMapper->SetInputConnection(glyph->GetOutputPort());
vtkActor *spikeActor = vtkActor::New();
spikeActor->SetMapper(spikeMapper);
ren1->AddActor(sphereActor);
ren1->AddActor(spikeActor);
ren1->SetBackground(0.2,0.3,0.4);
renWin->SetSize(300,300);
renWin->Render();
ren1->GetActiveCamera()->Zoom(1.4);
renWin->StereoRenderOn();
renWin->SetStereoTypeToRedBlue();
renWin->Render();

//changes and additions to the
// preceding example's source
vtkActor *spikeActor2 = vtkActor::New();
spikeActor2->SetMapper(spikeMapper);
spikeActor2->SetPosition(0,-0.7,0);
sphereActor2->SetPosition(0,-0.7,0);
ren1->AddActor(sphereActor2);
ren1->AddActor(spikeActor2);
// zoom in a little ren1->GetActiveCamera()->Zoom(1.5);
renWin->SetSubFrames(21);
for (i = 0; i <= 1.0; i = i + 0.05)
{
spikeActor2->RotateY(2);
sphereActor2->RotateY(2);
renWin->Render();
}
iren->Start();

Focal Depth¶
Now we will change the previous example to illustrate focal depth. First, we change the position of the bottom mace, moving it farther away from us. Since it is farther away it will appear smaller, so we scale it by a factor of two to maintain reasonable image size. We then remove the code for rendering the sub frames and instead set the number of frames for focal depth rendering. We also set the camera's focal point and focal disk to appropriate values. The resulting image and the required changes to the source code are shown in Figure 7-37.

vtkLineWidget¶
There are a variety of 3D widgets in VTK all of which function in a similar fashion. 3D widgets are a subclass of vtkInteractorObserver meaning that they are associated with a vtkRenderWindow and observe events in the render window (). (Note: vtkInteractorStyle---see "RenderWindowInteractor") ---is also a subclass of vtkInteractorObserver. The interactor style differs from a 3D widget in that it does not have a representation in the scene.) The following example shows the general approach to using a 3D widget using vtkLineWidget as an example (Figure 7-39). First the widget is instantiated and then placed. Placing means positioning, scaling, and orienting the widget consistent with the object on which they operate. By default, widgets are enabled with a "keypress-i" event, but the specific event to enable the widget can be modified.
The widget interfaces with the application through the command/observer event handling mechanism (see "Events and Observers". 3D widgets invoke several events, the most important being the StartInteractionEvent, InteractionEvent, and EndInteractionEvent. These events are typically invoked, for example, on mouse down, mouse move, and mouse up, respectively. In the example shown here, Tcl procedures are tied to the StartInteractionEvent and InteractionEvent using the AddObserver() method to produce streamlines as the widget is manipulated. Note that the streamline is seeded with a polygonal dataset each time an InteractionEvent is invoked using the GetPolyData() method. The pipeline update mechanism then automatically executes on the next render since the input to the streamline is modified.
Figure 7-39 Using the vtkLineWidget to produce streamtubes in the combustor dataset. The StartInteractionEvent turns the visibility of the streamlines on; the InteractionEvent causes the streamlines to regenerate themselves ( LineWidget.tcl ).
7.20 Chapter Summary¶
Alpha opacity is a graphics method to simulate transparent objects. Compositing is the process of blending translucent samples in order. Alpha compositing requires the data to be ordered properly.
Texture mapping is a powerful technique to introduce additional detail into an image without extensive geometric modelling. Applying 2D texture maps to the surface of an object is analogous to pasting a picture. The location of the texture map is specified via texture coordinates.
Volume rendering is a powerful rendering technique to view the interior of inhomogeneous objects. Most volume rendering techniques can be classified as image-order or object-order, although some are a combination of the two while others do not fall into either category. Object-order techniques generally composite voxels in front-to-back or back-to-front order. Image-order techniques cast rays through pixels in the image plane to sample the volume. Other methods may traverse both the image and the volume at the same time or may operate in the frequency domain. For effective visualization of volumetric data, classification and shading are important considerations. Regions of interest may be used to reduce the amount of data visible in an image. Due to the complexity of volume rendering algorithms, efficiency and methods that allow for interactivity are critical.
Stereo rendering techniques create two separate views for the right and left eyes. This simulates binocular parallax and allows us to see depth in the image. Time multiplexed techniques alternate left and right eye views in rapid succession. Time parallel techniques display both images at the same time.
Raster devices often suffer from aliasing effects. Anti-aliasing techniques are used to minimize the effects of aliasing. These techniques create blended images that soften the boundary of hard edges.
By using an accumulation buffer we can create interesting effects, including motion blur and focal blur. In motion blurring we accumulate multiple renders as the actors move. To simulate focal blur, we jitter the camera position and hold its focal point constant.
Effective visualizations are inherently interactive. Not only are camera manipulation models required for different types of data, but methods to interact, query, and modify data are essential. 3D widgets are important contributions to this end. They provide intuitive graphical interface to the data through a representation in the scene that can be easily manipulated. 3D widgets also generate supplemental information such as implicit functions, output polygonal data, and transformation matrices that may be applied to objects in the scene.
7.21 Bibliographic Notes¶
An overview of volume rendering and volume visualization techniques can be found in a tutorial by Kaufman [Kaufman91]. Many of the volume rendering techniques discussed in this chapter are also accessible from research institutions as source code. The shear-warp algorithm is provided within the VolPack rendering library and is available on the Web at graphics.stanford.edu/software/volpack/. SUNY Stony Brook offers a turnkey volume visualization system called VolVis to nonprofit and government organizations. Source code and executable versions are available at http://www.cs.sunysb.edu/\~volvis. In addition, an application called Vis5D is available that applies volume visualization techniques to time varying atmospheric weather data. Vis5D may be obtained from the Web location http://vis5d.sourceforge.net. A commercial volume rendering application, VolView, developed on top of The Visualization Toolkit, is available from Kitware for a 30-day trial at http://www.kitware.com/products/volview.html
7.22 References¶
[Cabral94] B. Cabral, N. Cam, J. Foran. "Accelerated Volume Rendering and Tomographic Reconstruction Using Texture Mapping Hardware." In Proceedings of 1994 Symposium on Volume Visualization. pp. 91--98, October 1994.
[Cignoni96] P. Cignoni, C. Montani, E. Puppo, R. Scopigno. "Optimal Isosurface Extraction from Irregular Volume Data." In Proceedings of 1996 Symposium on Volume Visualization. pp. 31--38, IEEE Computer Society Press, Los Alamitos, CA, October 1996.
[Drebin88] R. A. Drebin, L. Carpenter, P. Hanrahan. "Volume Rendering." Computer Graphics. 22(4):64--75 (Siggraph 1988).
[Hodges92] L. F. Hodges. "Tutorial: Time-Multiplexed Stereoscopic Computer Graphics." IEEE Computer Graphics & Applications. March 1992.
[Kaufman91] A. Kaufman (ed.). Volume Visualization. IEEE Computer Society Press, Los Alamitos, CA, 1991.
[Kaufman93] A. Kaufman, R. Yagel, D. Cohen. "Volume Graphics." IEEE Computer. 26(7):51--64, July 1993.
[Kelly94] M. Kelly, K. Gould, S. Winner, A. Yen. "Hardware Accelerated Rendering of CSG and Transparency." Computer Graphics (SIGGRAPH '94 ). pp. 177-184.
[Kikinis96] R. Kikinis, M. Shenton, D. Iosifescu, R. McCarley, P. Saiviroonporn, H. Hokama, A. Robatino, D. Metcalf, C. Wible, C. Portas, R. Donnino, F. Jolesz. "A Digital Brain Atlas for Surgical Planning, Model Driven Segmentation and Teaching." IEEE Transactions on Visualization and Computer Graphics. 2(3), September 1996.
[Krueger91] W. Krueger. "The Application of Transport Theory to Visualization of 3D Scalar Data Fields." Computers in Physics. pp. 397-406, July/August 1994.
[Lacroute94] P. Lacroute and M. Levoy. "Fast Volume Rendering Using a Shear-Warp Factorization of the Viewing Transformation." In Proceedings of SIGGRAPH '94. pp. 451-458, Addison-Wesley, Reading, MA, 1994.
[Laur91] D. Laur and P. Hanrahan. "Hierarchical Splatting: A Progressive Refinement Algorithm for Vol-ume Rendering." In Proceedings of SIGGRAPH '91. 25:285--288, 1991.
[Levoy88] M. Levoy. "Display of Surfaces from Volumetric Data." IEEE Computer Graphics & Applica-lions. 8(3), pp. 29--37, May 1988.
[Purciful95] J.T. Purciful. \"Three-Dimensional Widgets for Scientific Visualization and Animation.\" Masters Thesis, Dept. of Computer Science, UN iv. of Utah, 1995.
[Shirley90] P. Shirley and A. Tuchman. "A Polygonal Approximation to Direct Volume Rendering." Comput-er Graphics. 24(5):63--70, 1990.
[Silva96] C. Silva, J. S. B. Mitchell, A. E. Kaufman. "Fast Rendering of Irregular Grids." In Proceedings of 1996 Symposium on Volume Visualization. pp. 15--22, IEEE Computer Society Press, Los Alamitos, CA, October 1996.
[Sobierajski95] L. Sobierajski and R. Avila. "A Hardware Acceleration Method for Volumetric Ray Tracing." In Proceedings of Visualization '95. pp. 27-34, IEEE Computer Society Press, Los Alamitos, CA, October 1995.
[Totsuka92] T. Totsuka and M. Levoy. "Frequency Domain Volume Rendering." Computer Graphics (SIG-GRAPH '93). pp. 271--278, August 1993.
[Wernecke94] J. Wernecke. The Inventor Mentor. Addison-Wesley, Reading MA,1994.
[Westover90] L. Westover. "Footprint Evaluation for Volume Rendering." Computer Graphics (SIGGRAPH '90). 24(4):36, 1990.
[Wilhelms91] J. Wilhelms and A. Van Gelder. "A Coherent Projection Approach for Direct Volume Rendering." Computer Graphics (SIGGRAPH '91). 25(4):275--284, 1991.
[Wilhelms96] J. P. Wilhelms, A. Van Gelder, P. Tarantino, J. Gibbs. "Hierarchical and Parallelizable Direct Vol-ume Rendering for Irregular and Multiple Grids." In Proceedings of Visualization '96. pp. 73-80, IEEE Computer Society Press, Los Alamitos, CA, October 1996.
[Yagel92a] R. Yagel, D. Cohen, and A. Kaufman. "Normal Estimation in 3D Discrete Space." The Visual Computer. pp. 278--291, 1992.
[Yagel92b] R. Yagel and A. Kaufman. "Template-based Volume Viewing." In Proceedings of Eurographics '92. pp. 153--167, September 1992.
[Zeleznik93] R. C. Zeleznik, K. P. Herndon, D. C. Robbins, N. Huang, T. Meyer, N. Parker, J. F. Hughes. "An Interactive Toolkit for Constructing 3D Interfaces." Computer Graphics (Proceedings of Siggraph '93). 27(4):81--84. July 1993.
[Zuiderveld92] K. J. Zuiderveld, A. h. j. Koning, and M. A. Viergever. "Acceleration of Ray-Casting Using 3D Distance Transforms." In Proceedings of Visualization and Biomedical Computing, pp. 324--335, October 1992.
7.23 Exercises¶
7.1 In astronomy, photographs can be taken that show the movements of the stars over a period of time by keeping the camera's shutter open. Without accounting for the rotation of the earth, these photographs display a swirl of circular arcs all centered about a common point. Such time lapse photography is essentially capturing motion blur. If we tried to simulate these images using the motion blur technique described in this chapter, they would look different from the photographs. Why is this? How could you change the simple motion blur algorithm to correct this?
7.2 In Figure 7-25 we show the difference between stereo rendering with two or one view planes. If you were viewing a rectangle head-on (its surface normal parallel to your direction), what artifacts would be introduced by rendering onto one view plane while using the equations for two planes?
7.3 On some graphics systems transparent objects are rendered using a technique called screen door transparency. Basically, every pixel is either completely opaque or completely transparent. Any value in between is approximated using dithering. So a polygon that was 50 percent opaque would be rendered by drawing only half of the pixels. What visual artifacts does this introduce? What blending problems can arise in using such a technique?
7.4 In this chapter we describe a few different techniques for anti-aliased rendering. One technique involved rendering a large image and then scaling it down to the desired size using bilinear interpolation. Another technique involved rendering multiple images at the desired size using small camera movements and then accumulating them into a final image. When rendering a model with a surface representation, these two techniques will produce roughly the same result. When rendering a model with a wireframe representation there will be significant differences. Why is this?
7.5 You need to create a small image of a volume dataset to include on your web page. The dataset contains voxels,512 and the desired image size is pixels.You100can use a software object-order method that projects each voxel onto the image, or a software ray casting method that casts one ray for each pixel. Assuming that identical images are created, which method would you select, and why? 7.6 Two software developers implement volume rendering methods. The first developer uses a software ray casting approach, while the second uses a graphics hardware texture mapping approach. The grayscale images are generated and displayed on a workstation with an 8 bit frame buffer (256 levels of gray). They both use the same interpolation method and the same compositing scheme, yet the two methods produce different images even though the same number of samples from identical locations were used to generate the images. Why is this?
7.7 In the classification of some medical dataset, scalar values from 100 to 200 represent skin, 200 to 300 represent muscle and 300 to 400 represent bone. The color transfer functions define skin as tan, muscle as red, and bone as white. If we interpolate scalar value and then perform classification, what classification artifacts may appear in the image?
7.8 The normal encoding example illustrated in Figure 7-22 produced 82 indices at a recursion depth of two, which would require seven bits of storage. If we instead use a recursion depth of three, how many indices are there? How many unique vector directions does this represent? How many bits of storage does this require?
7.9 Writing an object-order back-to-front projection algorithm is more difficult for a perspective viewing transformation than a parallel viewing transformation. Explain why this is and draw a 2D diagram of the volume and the viewing frustum that illustrates the issues.