Chapter 12 - Applications¶
We have described the design and implementation of an extensive toolkit of visualization techniques. In this chapter we examine several case studies to show how to use these tools to gain insight into important application areas. These areas are medical imaging, financial visualization, modelling, computational fluid dynamics, finite element analysis, and algorithm visualization. For each case, we briefly describe the problem domain and what information we expect to obtain through visualization. Then we craft an approach to show the results. Many times we will extend the functionality of the Visualization Toolkit with application-specific tools. Finally, we present a sample program and show resulting images.
The visualization design process we go through is similar in each case. First, we read or generate application-specific data and transform it into one of the data representation types in the Visualization Toolkit. Often this first step is the most difficult one because we have to write custom computer code, and decide what form of visualization data to use. In the next step, we choose visualizations for the relevant data within the application. Sometimes this means choosing or creating models corresponding to the physical structure. Examples include spheres for atoms, polygonal surfaces to model physical objects, or computational surfaces to model flow boundaries. Other times we generate more abstract models, such as isosurfaces or glyphs, corresponding to important application data. In the last step we combine the physical components with the abstract components to create a visualization that aids the user in understanding the data.
12.1 3D Medical Imaging¶
Radiology is a medical discipline that deals with images of human anatomy. These images come from a variety of medical imaging devices, including X-ray, X-ray Computed Tomography (CT), Magnetic Resonance Imaging (MRI), and ultrasound. Each imaging technique, called an imaging modality, has particular diagnostic strengths. The choice of modality is the job of the radiologist and the referring physician. For the most part, radiologists deal with two-dimensional images, but there are situations when three-dimensional models can assist the radiologist's diagnosis. Radiologists have special training to interpret the two dimensional images and understand the complex anatomical relationships in these two-dimensional representations. However, in dealing with referring physicians and surgeons, the radiologist sometimes has difficulty communicating these relationships. After all, a surgeon works in three-dimensions during the planning and execution of an operation; moreover, they are much more comfortable looking at and working with three-dimensional models.
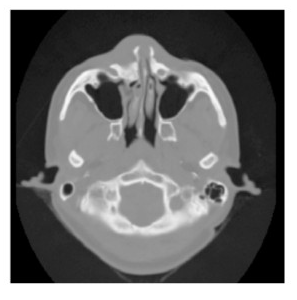
This case study deals with CT data. Computed tomography measures the attenuation of X-rays as they pass through the body. A CT image consists of levels of gray that vary from black (for air), to gray (for soft tissue), to white (for bone). Figure 12-1 shows a CT cross section through a head. This slice is taken perpendicular to the spine approximately through the middle of the ears. The gray boundary around the head clearly shows the ears and bridge of the nose. The dark regions on the interior of the slice are the nasal passages and ear canals. The bright areas are bone. This study contains 93 such slices, spaced 1.5 mm apart. Each slice has 256*^2 pixels spaced 0.8 mm apart with 12 bits of gray level.
Our challenge is to take this gray scale data (over 12 megabytes) and convert it into information that will aid the surgeon. Fortunately, our visualization toolkit has just the right techniques. We will use isocontouring techniques to extract the skin and bone surfaces and display orthogonal cross-sections to put the isosurface in context. From experience we know that a density value of 500 will define the air/skin boundary, and a value of 1150 will define the soft tissue/bone boundary. In VTK terminology, medical imaging slice data is image data. Recall from Chapter 5 that for image data, the topology and geometry of the data is implicitly known, requiring only dimensions, an origin, and the data spacing.
The steps we follow in this case study are common to many three-dimensional medical studies.
-
Read the input.
-
For each anatomical feature of interest, create an isosurface.
-
Transform the models from patient space to world space.
-
Render the models.
This case study describes in detail how to read input data and extract anatomical features using iso-contouring. Orthogonal planes will be shown using a texture-based technique. Along the way we will also show you how to render the data. We finish with a brief discussion of medical data transformations. This complete source code for the examples shown in this section are available from Medical1.cxx, Medical2.cxx, and Medical3.cxx.
Read the Input
Medical images come in many flavors of file formats. This study is stored as flat files without header information. Each 16-bit pixel is stored with little-endian byte order. Also, as is often the case, each slice is stored in a separate file with the file suffix being the slice number of the form prefix.1, prefix.2 , and so on. Medical imaging files often have a header of a certain size before the image data starts. The size of the header varies from file format to file format. Finally, another complication is that sometimes one or more bits in each 16-bit pixel is used to mark connectivity between voxels. It is important to be able to mask out bits as they are read.
VTK provides several image readers including one that can read raw formats of the type described above [vtkVolume16Reader](https://www.vtk.org/doc/nightly/html/classvtkVolume16Reader.html). To read this data we instantiate the class and set the appropriate instance variables as follows.
vtkVolume16Reader *v16 = vtkVolume16Reader::New();
v16->SetDataDimensions (64,64); v16->SetImageRange (1,93);
v16->SetDataByteOrderToLittleEndian();
v16->SetFilePrefix ("headsq/quarter");
v16->SetDataSpacing (3.2, 3.2, 1.5);
The FilePrefix and FilePattern instance variable work together to produce the name of files in a series of slices. The FilePattern which by default is %s.%d generates the filename to read by performing a C-language sprintf() of the FilePrefix and the current file number into the FilePattern format specifier.
Create an Isosurface
We can choose from three techniques for isosurface visualization: volume rendering, marching cubes, and dividing cubes. We assume that we want to interact with our data at the highest possible speed, so we will not use volume rendering. We prefer marching cubes if we have polygonal rendering hardware available, or if we need to move up close to or inside the extracted surfaces. Even with hardware assisted rendering, we may have to reduce the polygon count to get reasonable rendering speeds. Dividing cubes is appropriate for software rendering. For this application we'll use marching cubes.
For medical volumes, marching cubes generates a large number of triangles. To be practical, we'll do this case study with a reduced resolution dataset. We took the original 256^2 data and reduced it to 64^2 slices by averaging neighboring pixels twice in the slice plane. We call the resulting dataset quarter since it has 1/4 the resolution of the original data. We adjust the DataSpacing for the reduced resolution dataset to 3.2 mm per pixel. Our first program will generate an isosurface for the skin.
The flow in the program is similar to most VTK applications.
-
Generate some data.
-
Process it with filters.
-
Create a mapper to generate rendering primitives.
-
Create actors for all mappers.
-
Render the results.
The filter we have chosen to use is vtkMarchingCubes. We could also use vtkContourFilter since it will automatically create an instance of vtkMarchingCubes as it delegates to the fastest subclass for a particular dataset type. The class vtkPolyDataNormals is used to generate nice surface normals for the data. vtkMarchingCubes can also generate normals, but sometimes better results are achieved when the normals are directly from the surface (vtkPolyDataNormals ) versus from the data (vtkMarchingCubes ). To complete this example, we take the output from the isosurface generator vtkMarchingCubes and connect it to a mapper and actor via vtkPolyDataMapper and vtkActor. The C++ code follows.
vtkContourFilter *skinExtractor = vtkContourFilter::New();
skinExtractor->SetInputConnection(v16->GetOutputPort());
skinExtractor->SetValue(0, 500);
vtkPolyDataNormals *skinNormals = vtkPolyDataNormals::New();
skinNormals->SetInputConnection(skinExtractor->GetOutputPort());
skinNormals->SetFeatureAngle(60.0);
vtkPolyDataMapper *skinMapper = vtkPolyDataMapper::New();
skinMapper->SetInputConnection(skinNormals->GetOutputPort());
skinMapper->ScalarVisibilityOff();
vtkActor *skin = vtkActor::New();
skin->SetMapper(skinMapper);
vtkOutlineFilter *outlineData = vtkOutlineFilter::New();
outlineData->SetInputConnection(v16->GetOutputPort());
vtkPolyDataMapper *mapOutline = vtkPolyDataMapper::New();
mapOutline->SetInputConnection(outlineData->GetOutputPort());
vtkActor *outline = vtkActor::New();
outline->SetMapper(mapOutline);
outline->GetProperty()->SetColor(0,0,0);
vtkCamera *aCamera = vtkCamera::New();
aCamera->SetViewUp (0, 0, -1);
aCamera->SetPosition (0, 1, 0);
aCamera->SetFocalPoint (0, 0, 0);
aCamera->ComputeViewPlaneNormal();
aRenderer->AddActor(outline);
aRenderer->AddActor(skin);
aRenderer->SetActiveCamera(aCamera);
aRenderer->ResetCamera ();
aCamera->Dolly(1.5);
aRenderer->SetBackground(1,1,1);
renWin->SetSize(640, 480);
aRenderer->ResetCameraClippingRange ();
// Initialize the event loop and then start it.
iren->Initialize();
iren->Start();
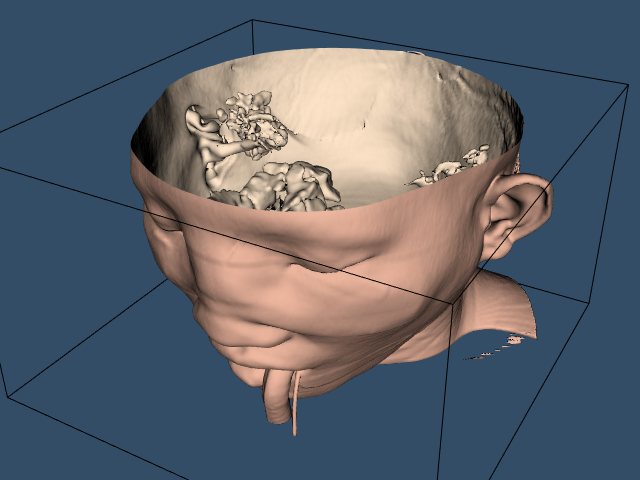
To provide context for the isosurface an outline is created around the data. An initial view is set up in a window size of 640 \times 480 pixels. Since the dolly command moves the camera towards the data, the clipping planes are reset to insure that the isosurface is completely visible. Figure 12-2 shows the resulting image of the patient's skin.
We can improve this visualization in a number of ways. First, we can choose a more appropriate color (and other surface properties) for the skin. We use the vtkProperty method SetDiffuseColor() to set the skin color to a fleshy tone. We also add a specular component to the skin surface. Next, we can add additional isosurfaces corresponding to various anatomical features. Here we choose to extract the bone surface by adding an additional pipeline segment. This consists of the filters vtkMarchingCubes, vtkPolyDataMapper, and vtkActor, just as we did with the skin. Finally, to improve rendering performance on our system, we create triangle strips from the output of the contouring process. This requires adding vtkStripper.
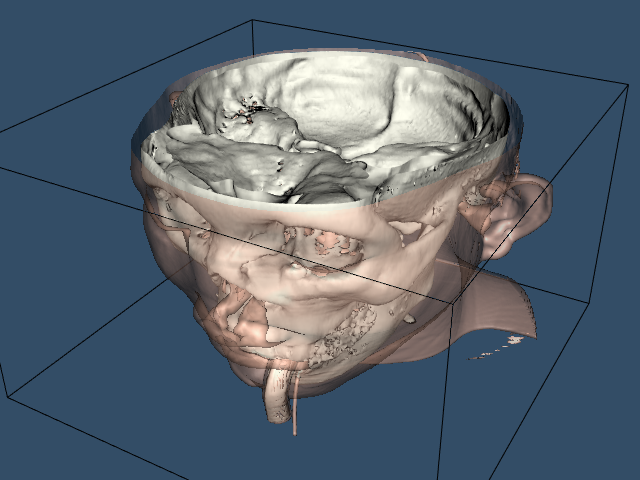
Figure 12-3 shows the resulting image, and the following is the C++ code for the pipeline.
vtkActor *skin = vtkActor::New();
skin->SetMapper(skinMapper);
skin->GetProperty()->SetDiffuseColor(1, .49, .25);
skin->GetProperty()->SetSpecular(.3);
skin->GetProperty()->SetSpecularPower(20);
skin->GetProperty()->SetOpacity(1.0);
vtkContourFilter *boneExtractor = vtkContourFilter::New();
boneExtractor->SetInputConnection(v16->GetOutputPort());
boneExtractor->SetValue(0, 1150);
vtkPolyDataNormals *boneNormals = vtkPolyDataNormals::New();
boneNormals->SetInputConnection(boneExtractor->GetOutputPort());
boneNormals->SetFeatureAngle(60.0);
vtkStripper *boneStripper = vtkStripper::New();
boneStripper->SetInputConnection(boneNormals->GetOutputPort());
vtkPolyDataMapper *boneMapper = vtkPolyDataMapper::New();
boneMapper->SetInputConnection(boneStripper->GetOutputPort());
boneMapper->ScalarVisibilityOff();
vtkActor *bone = vtkActor::New(); bone->SetMapper(boneMapper);
bone->GetProperty()->SetDiffuseColor(1, 1, .9412);
The Visualization Toolkit provides other useful techniques besides isocontouring for exploring volume data. One popular technique used in medical imaging is to view orthogonal slices, or planes, through the data. Because computer graphics hardware supports texture mapping, an approach using texture mapping gives the best result in terms or interactive performance.
We will extract three orthogonal planes corresponding to the axial, sagittal, and coronal cross sections that are familiar to radiologists. The axial plane is perpendicular to the patient's neck, sagittal passes from left to right, and coronal passes from front to back. For illustrative purposes, we render each of these planes with a different color lookup table. For the sagittal plane, we use a gray scale. The coronal and axial planes vary the saturation and hue table, respectively. We combine this with a translucent rendering of the skin (we turn off the bone with the C++ statement bone->VisibilityOff() ). The following VTK code creates the three lookup tables that is used in the texture mapping process.
vtkLookupTable *bwLut = vtkLookupTable::New();
bwLut->SetTableRange (0, 2000);
bwLut->SetSaturationRange (0, 0);
bwLut->SetHueRange (0, 0);
bwLut->SetValueRange (0, 1);
vtkLookupTable *hueLut = vtkLookupTable::New();
hueLut->SetTableRange (0, 2000);
hueLut->SetHueRange (0, 1);
hueLut->SetSaturationRange (1, 1);
hueLut->SetValueRange (1, 1);
vtkLookupTable *satLut = vtkLookupTable::New();
satLut->SetTableRange (0, 2000);
satLut->SetHueRange (.6, .6);
satLut->SetSaturationRange (0, 1);
satLut->SetValueRange (1, 1);
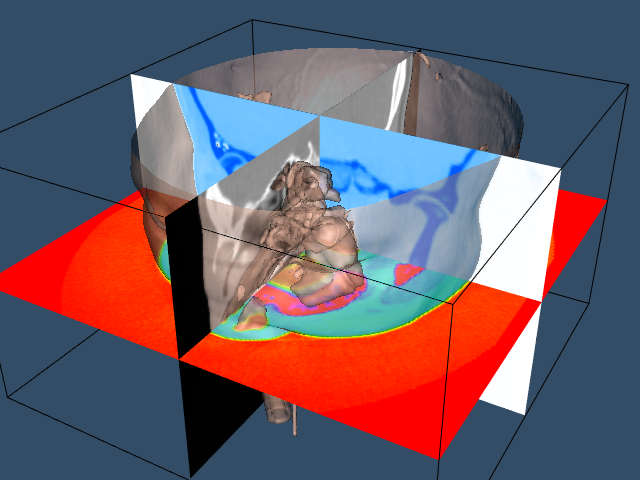
The image data is mapped to colors using the filter vtkImageMapToColors in combination with the lookup tables created above. The actual display of the slice is performed with vtkImageActor (see "Assemblies and Other Types of vtkProp" in Chapter 3 for more information). This class conveniently combines a quadrilateral, polygon plane with a texture map. vtkImageActor requires image data of type unsigned char, which the class vtkImageMapToColors conveniently provides. To avoid copying the data and to specify the 2D texture to use, the DisplayExtent of each vtkImageActor is set appropriately. The C++ code is as follows:
// saggital
vtkImageMapToColors *saggitalColors = vtkImageMapToColors::New();
saggitalColors->SetInputConnection(v16->GetOutputPort());
saggitalColors->SetLookupTable(bwLut);
vtkImageActor *saggital = vtkImageActor::New();
saggital->SetInputConnection(saggitalColors->GetOutputPort());
saggital->SetDisplayExtent(32,32, 0,63, 0,92);
// axial
vtkImageMapToColors *axialColors = vtkImageMapToColors::New();
axialColors->SetInputConnection(v16->GetOutputPort());
axialColors->SetLookupTable(hueLut);
vtkImageActor *axial = vtkImageActor::New();
axial->SetInputConnection(axialColors->GetOutputPort());
axial->SetDisplayExtent(0,63, 0,63, 46,46);
// coronal
vtkImageMapToColors *coronalColors = vtkImageMapToColors::New();
coronalColors->SetInputConnection(v16->GetOutputPort());
coronalColors->SetLookupTable(satLut);
vtkImageActor *coronal = vtkImageActor::New();
coronal->SetInputConnection(coronalColors->GetOutputPort());
coronal->SetDisplayExtent(0,63, 32,32, 0,92);
aRenderer->AddActor(outline);
aRenderer->AddActor(saggital);
aRenderer->AddActor(axial);
aRenderer->AddActor(coronal);
aRenderer->AddActor(bone);
aRenderer->AddActor(skin);
Figure 12-4 shows the resulting composite image.
In this example, the actor named skin is rendered last because we are using a translucent surface. Recall from "Transparency and Alpha Values" in Chapter 7 that we must order the polygons composing transparent surfaces for proper results. We render the skin last by adding it to aRenderer's actor list last.
We need to make one last point about processing medical imaging data. Medical images can be acquired in a variety of orders that refer to the relationship of consecutive slices to the patient. Radiologists view an image as though they were looking at the patient's feet. This means that on the display, the patient's left appears on the right. For CT there are two standard orders: top to bottom or bottom to top. In a top to bottom acquisition, slice i is farther from the patient's feet than slice i - 1. Why do we worry about this order? It is imperative in medical applications that we retain the left / right relationship. Ignoring the slice acquisition order can result in a flipping of left and right. To correct this, we need to transform either the original dataset or the geometry we have extracted. (See "Exercises" in this Chapter for more information.) Also, you may wish to examine the implementation of the classes vtkVolume16Reader and vtkVolumeReader (the superclass of vtkVolume16Reader). These classes have special methods that deal with transforming image data.
12.2 Creating Models from Segmented Volume Data¶
The previous example described how to create models from gray-scale medical imaging data. The techniques for extracting bone and skin models is straightforward compared to the task of generating models of other soft tissue. The reason is that magnetic resonance and, to some extent, computed tomography, generates similar gray-scale values for different tissue types. For example, the liver and kidney in a medical computed tomography volume often have overlapping intensities. Likewise, many different tissues in the brain have overlapping intensities when viewed with magnetic resonance imaging. To deal with these problems researchers apply a process called segmentation to identify different tissues. These processes vary in sophistication from almost completely automatic methods to manual tracing of images. Segmentation continues to be a hot research area. Although the segmentation process itself is beyond the scope of this text, in this case study we show how to process segmented medical data.
For our purposes we assume that someone (or many graduate students) have laboriously labeled each pixel in each slice of a volume of data with a tissue identifier. This identifier is an integer number that describes which tissue class each pixel belongs to. For example, we may be given a series of MRI slices of the knee with tissue numbers defining the meniscus, femur, muscles, and so forth. Figure 12-5 shows two representations of a slice from a volume acquired from a patient's knee. The image on the left is the original MRI slice; the image on the right contains tissue labels for a number of important organs. The bottom image is a composite of the two images.
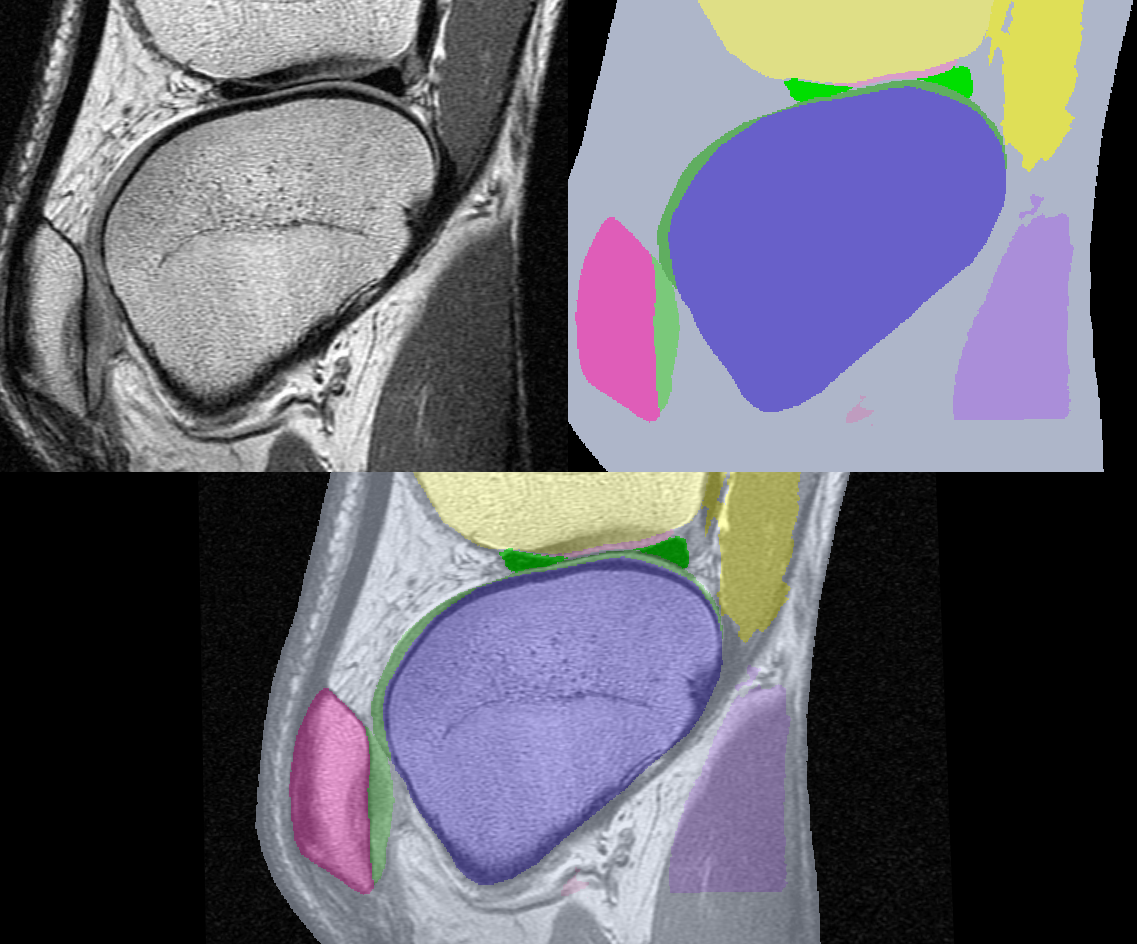
Notice the difference in the information presented by each representation. The original slice shows gradual changes at organ borders, while the segmented slice has abrupt changes. The images we processed in the previous CT example used marching cubes isocontouring algorithm and an intensity threshold to extract the isosurfaces. The segmented study we present has integer labels that have a somewhat arbitrary numeric value. Our goal in this example is to somehow take the tissue labels and create grayscale slices that we can process with the same techniques we used previously. Another goal is to show how image processing and visualization can work together in an application.
The Virtual Frog
To demonstrate the processing of segmented data we will use a dataset derived from a frog. This data was prepared at Lawrence Berkeley National Laboratories and is included with their permission on the CD-ROM accompanying this book. The data was acquired by physically slicing the frog and photographing the slices. The original segmented data is in the form of tissue masks with one file per tissue. There are 136 slices per tissue and 15 different tissues. Each slice is 470 by 500 pixels. (To accommodate the volume readers we have in VTK, we processed the mask files and combined them all in one file for each slice.) We used integer numbers 1-15 to represent the 15 tissues. Figure 12-6 shows an original slice, a labeled slice, and a composite of the two representations.
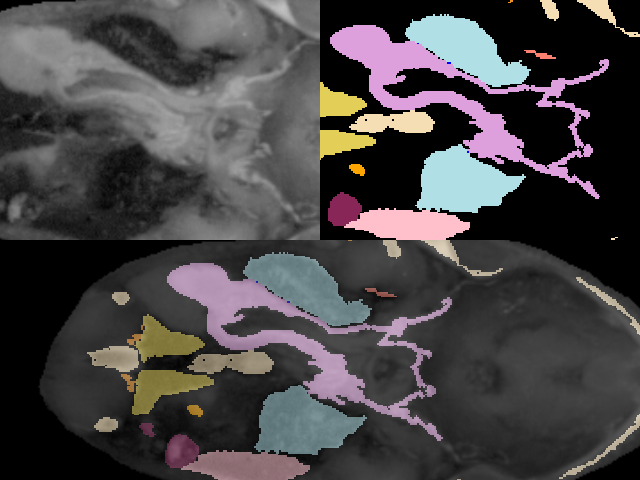
Before we describe the process to go from binary labeled tissues to gray-scale data suitable for isosurface extraction, compare the two images of the frog's brain shown in Figure 12-7. On the left is a surface extracted using a binary labeling of the brain. The right image was created using the visualization pipeline that we will develop in this example.
Developing a Strategy
In the last example, we used C++ and created a program that was tailored to extract two surfaces: one of the skin and one of the bone. All the parameters for the surface extraction were hard-coded in the source. Since our frog has 15 different tissues; we seek a more general solution to this problem. We may have to experiment with a number of different parameters for a number of visualization and imaging filters. Our goal is to develop a general pipeline that will work not only our 15 tissues but on other medical datasets as well. We'll design the program to work with a set of user-specified parameters to control the elements of the pipeline. A reasonable description might look like:
STUDY = 'frogTissue'
SLICE_ORDER = 'hfsi'
ROWS = 470
COLUMNS = 500
PIXEL_SIZE = 1
SPACING = 1.5
plus possibly many more parameters to control decimation, smoothing, and so forth. Working in C++, we would have to design the format of the file and write code to interpret the statements.
We make the job easier here by using Python. Another decision is to separate the modelling from the rendering. However, in order to simplify things we will be using one Python script, FrogReconstruction.py.
In the real world, our script would be modified to generate models in a "batch" mode. If this is done, we would run run one VTK Python script for each tissue. That script will create a .vtk output file containing the polygonal representation of each tissue. Later, we would render the models with a separate script.
Overview of the Pipeline
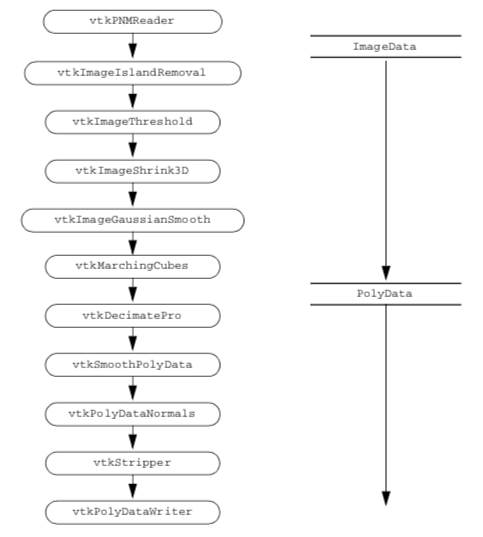
Figure 12-8 shows the design of the pipeline. This generic pipeline has been developed over the years in our laboratory and in the Brigham and Women's Hospital Surgical Planning Lab. We find that it produces reasonable models from segmented datasets. Do not be intimidated by the number of filters (twelve in all). Before we developed VTK, we did similar processing with a hodgepodge of programs all written with different interfaces. We used intermediate files to pass data from one filter to the next. The new pipeline, implemented in VTK, is more efficient in time and computing resources.
We use the convention that user-specified variables are in capital letters. First we show the elements of the pipeline and subsequently show sample functions that extract 3D models of the frog's tissues.
Read the Segmented Volume Data
We assume here that all the data to be processed was acquired with a constant center landmark. In VTK, the origin of the data applies to the lower left of an image volume. In this pipeline, we calculate the origin such that the x,y center of the volume will be (0,0). The DataSpacing describes the size of each pixel and the distance between slices. DataVOI selects a volume of interest (VOI). A VOI lets us select areas of interest, sometimes eliminating extraneous structures like the CT table bed. For the frog, we have written a small C program that reads the tissue label file and finds the volume of interest for each tissue.
The SetTransform() method defines how to arrange the data in memory. Medical images can be acquired in a variety of orders. For example, in CT, the data can be gathered from top to bottom (superior to inferior), or bottom to top (inferior to superior). In addition, MRI data can be acquired from left to right, right to left, front-to-back (anterior to posterior) or back-to-front. This filter transforms triangle vertices such that the resulting models will all "face" the viewer with a view up of (0,-1,0), looking down the positive z axis. Also, proper left-right correspondence will be maintained. That means the patient's left will always be left on the generated models. Look in SliceOrder.tcl to see the permutations and rotations for each order.
In the example, we have created a class called \texttt{SliceOrder} which handles the permutations and rotations for each order.
We will be using a [vtkMetaImageReader](https://www.vtk.org/doc/nightly/html/classvtkMetaImageReader.html)() instead of the [vtkPNMReader](https://www.vtk.org/doc/nightly/html/classvtkPNMReader.html)() since the data has been collected into metaa-image files. This means that we will apply the transform later in the pipeline.
All the other parameters are self-explanatory.
reader = vtk.vtkMetaImageReader()
reader.SetFileName(str(fn))
reader.SetDataSpacing(data_spacing)
reader.SetDataOrigin(data_origin)
reader.SetDataExtent(voi)
reader.Update()
Remove Islands
Some segmentation techniques, especially those that are automatic, may generate islands of misclassified voxels. This filter looks for connected pixels with the ISLAND_REPLACE label, and if the number of connected pixels is less than ISLAND_AREA, it replaces them with the label TISSUE. Note that this filter is only executed if ISLAND_REPLACE is positive.
last_connection = reader
if tissue['ISLAND_REPLACE'] >= 0:
island_remover = vtk.vtkImageIslandRemoval2D()
island_remover.SetAreaThreshold(tissue['ISLAND_AREA'])
island_remover.SetIslandValue(tissue['ISLAND_REPLACE'])
island_remover.SetReplaceValue(tissue['TISSUE'])
island_remover.SetInput(last_connection.GetOutput())
island_remover.Update()
last_connection = island_remover
Select a Tissue
The rest of the pipeline requires gray-scale data. To convert the volume that now contains integer tissue labels to a gray-scale volume containing only one tissue, we use the threshold filter to set all pixels with the value TISSUE (the tissue of choice for this pipeline) to 255 and all other pixels to 0. The choice of 255 is somewhat arbitrary.
select_tissue = vtk.vtkImageThreshold()
select_tissue.ThresholdBetween(tissue['TISSUE'], tissue['TISSUE'])
select_tissue.SetInValue(255)
select_tissue.SetOutValue(0)
select_tissue.SetInputConnection(last_connection.GetOutputPort())
Resample the Volume
Lower resolution volumes produce fewer polygons. For experimentation we often reduce the resolution of the data with this filter. However, details can be lost during this process. Averaging creates new pixels in the resampled volume by averaging neighboring pixels. If averaging is turned off, every SAMPLE_RATE pixel will be passed through to the output.
shrinker = vtk.vtkImageShrink3D()
shrinker.SetInputConnection(select_tissue.GetOutputPort())
shrinker.SetShrinkFactors(tissue['SAMPLE_RATE'])
shrinker.AveragingOn()
last_connection = shrinker
Smooth the Volume Data
To this point, unless we have resampled the data, the volume is labeled with a value of 255 in pixels of the selected tissue and 0 elsewhere. This "binary" volume would produce stepped surfaces if we did not blur it. The Gaussian kernel specified in this filter accomplishes the smoothing we require to extract surfaces. The amount of smoothing is controlled by GAUSSIAN_STANDARD_DEVIATION that can be independently specified for each axis of the volume data. We only run this filter if some smoothing is requested,
if not all(v == 0 for v in tissue['GAUSSIAN_STANDARD_DEVIATION']):
gaussian = vtk.vtkImageGaussianSmooth()
gaussian.SetStandardDeviation(*tissue['GAUSSIAN_STANDARD_DEVIATION'])
gaussian.SetRadiusFactors(*tissue['GAUSSIAN_RADIUS_FACTORS'])
gaussian.SetInputConnection(shrinker.GetOutputPort())
last_connection = gaussian
Generate Triangles
Now we can process the volume with an iso-surface generator just as though we had obtained gray-scale data from a scanner. We added a few more bells and whistles to the pipeline. The filter runs faster if we turn off gradient and normal calculations. The generator normally calculates vertex normals from the gradient of the volume data. In our pipeline, we have concocted a gray-scale representation and will subsequently decimate the triangle mesh and smooth the resulting vertices. This processing invalidates the normals that are calculated by the generator.
if flying_edges:
iso_surface = vtk.vtkFlyingEdges3D()
iso_surface.SetInputConnection(last_connection.GetOutputPort())
iso_surface.ComputeScalarsOff()
iso_surface.ComputeGradientsOff()
iso_surface.ComputeNormalsOff()
iso_surface.SetValue(0, iso_value)
Transform the Data We need to transform the data so the appropriate orientation is displayed.
so = SliceOrder()
transform = so.get('hfap')
transform.Scale(1, -1, 1)
tf = vtk.vtkTransformPolyDataFilter()
tf.SetTransform(transform)
tf.SetInputConnection(iso_surface.GetOutputPort())
Reduce the Number of Triangles
There are often many more triangles generated by the isosurfacing algorithm than we need for rendering. Here we reduce the triangle count by eliminating triangle vertices that lie within a user-specified distance to the plane formed by neighboring vertices. We preserve any edges of triangles that are considered "features."
decimator = vtk.vtkDecimatePro()
decimator.SetInputConnection(tf.GetOutputPort())
decimator.SetFeatureAngle(tissue['DECIMATE_ANGLE'])
decimator.MaximumIterations = tissue['DECIMATE_ITERATIONS']
decimator.PreserveTopologyOn()
decimator.SetErrorIsAbsolute(1)
decimator.SetAbsoluteError(tissue['DECIMATE_ERROR'])
decimator.SetTargetReduction(tissue['DECIMATE_REDUCTION'])
Smooth the Triangle Vertices
This filter uses Laplacian smoothing described in "Mesh Smoothing" in Chapter 9 to adjust triangle vertices as an "average" of neighboring vertices. Typically, the movement will be less than a voxel.
Of course we have already smoothed the image data with a Gaussian kernel so this step may not give much improvement; however, models that are heavily decimated can sometimes be improved with additional polygonal smoothing.
smoother = vtk.vtkSmoothPolyDataFilter()
smoother.SetInputConnection(decimator.GetOutputPort())
smoother.SetNumberOfIterations(tissue['SMOOTH_ITERATIONS'])
smoother.SetRelaxationFactor(tissue['SMOOTH_FACTOR'])
smoother.SetFeatureAngle(tissue['SMOOTH_ANGLE'])
smoother.FeatureEdgeSmoothingOff()
smoother.BoundarySmoothingOff()
smoother.SetConvergence(0)
Generate Normals
To generate smooth shaded models during rendering, we need normals at each vertex. As in decimation, sharp edges can be retained by setting the feature angle.
normals = vtk.vtkPolyDataNormals()
normals.SetInputConnection(smoother.GetOutputPort())
normals.SetFeatureAngle(tissue['FEATURE_ANGLE'])
Generate Triangle Strips
Triangle strips are a compact representation of large numbers of triangles. This filter processes our independent triangles before we write them to a file.
stripper = vtk.vtkStripper()
stripper.SetInputConnection(normals.GetOutputPort())
Write the Triangles to a File
Finally, if we were writing the triangle strips to a file, the last component of the pipeline would be:
writer = vtk.vtkPolyDataWriter()
writer.SetInputConnection(stripper.GetOutputPort())
writer.SetFileName(NAME + '.vtk')
Execute the Pipeline
If you have gotten this far in the book, you know that the Visualization Toolkit uses a demand-driven pipeline architecture and so far we have not demanded anything. We have just specified the pipeline topology and the parameters for each pipeline element. So we need to trigger the updating of the pipeline.
If you are displaying the image then:
render_window.Render()
If you are just writing to a file:
writer.Update()
causes the pipeline to execute. In practice we do a bit more than just Update the last element of the pipeline. We explicitly Update each element so that we can time the individual steps.
Specifying Parameters for the Pipeline
All of the variables mentioned above must be defined for each tissue to be processed. The parameters fall into two general categories. Some are specific to the particular study while some are specific to each tissue. For the frog, we collected the study-specific parameters in a function that contains:
def frog():
p = default_parameters()
p['ROWS'] = 470
p['COLUMNS'] = 500
p['STUDY'] = 'frogTissue'
p['SLICE_ORDER'] = 'si'
p['PIXEL_SIZE'] = 1
p['SPACING'] = 1.5
p['VALUE'] = 127.5
p['SAMPLE_RATE'] = [1, 1, 1]
p['GAUSSIAN_STANDARD_DEVIATION'] = [2, 2, 2]
p['DECIMATE_REDUCTION'] = 0.95
p['DECIMATE_ITERATIONS'] = 5
p['DECIMATE_ERROR'] = 0.0002
p['DECIMATE_ERROR_INCREMENT'] = 0.0002
p['SMOOTH_ITERATIONS'] = 0
p['SMOOTH_FACTOR'] = 0.1
return p
There is a specific function for each tissue type. This tissue-specific function reads in the frog-specific parameters, sets the tissue-specific parameters. For example, liver()) contains:
def liver():
p = frog()
p['NAME'] = 'liver'
p['TISSUE'] = 10
p['START_SLICE'] = 25
p['END_SLICE'] = 126
p['VOI'] = [167, 297, 154, 304, p['START_SLICE'], p['END_SLICE']]
return p
Parameters in the function frog() can also be overridden. For example, skeleton() overrides the standard deviation for the Gaussian filter.
def skeleton():
p = frog()
p['STUDY'] = 'frogTissue'
p['NAME'] = 'skeleton'
p['TISSUE'] = 13
p['VALUE'] = 64.5
p['START_SLICE'] = 1
p['END_SLICE'] = 136
p['VOI'] = [23, 479, 8, 469, p['START_SLICE'], p['END_SLICE']]
p['GAUSSIAN_STANDARD_DEVIATION'] = [1.5, 1.5, 1]
return p
Note that both of these examples specify a volume of interest. This improves performance of the imaging and visualization algorithms by eliminating empty space.
Another function, skin(), uses similar parameters, it is used to extract the skin. Island removal or threshold pipeline elements are not needed since the data is already has gray-scale information.
After the usual code to create required rendering objects, a single statement for each part creates an actor that we can add to the renderer:
t, actor = create_frog_actor(frog_fn, frog_tissue_fn, tissue, flying_edges, lut)
ict[name] = t
renderer.AddActor(actor)
The rest of the script defines a standard view.
# Initial view (looking down on the dorsal surface).
renderer.GetActiveCamera().Roll(-90)
renderer.ResetCamera()
Conclusion
This lengthy example shows the power of a comprehensive visualization system like VTK.
- We mixed image processing and computer graphics algorithms to process data created by an external segmentation process.
- We developed a generic approach that allows users to control the elements of the pipeline with a familiar scripting language, Python.
- We can easily separate this script into a "batch" portion and an "interactive" portion.
If .vtk files have been created we can use an alternative Python script called Frog.py. This takes the vtk models corresponding to the .vtk file and renders them.
These programs:
allow the user specify what tissues to display and also provide some pre-defined views.
Figure12-9 shows four views of the frog.
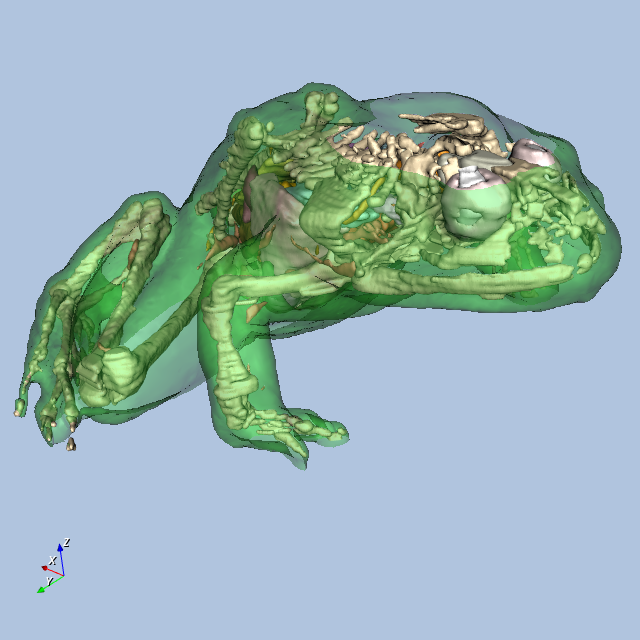
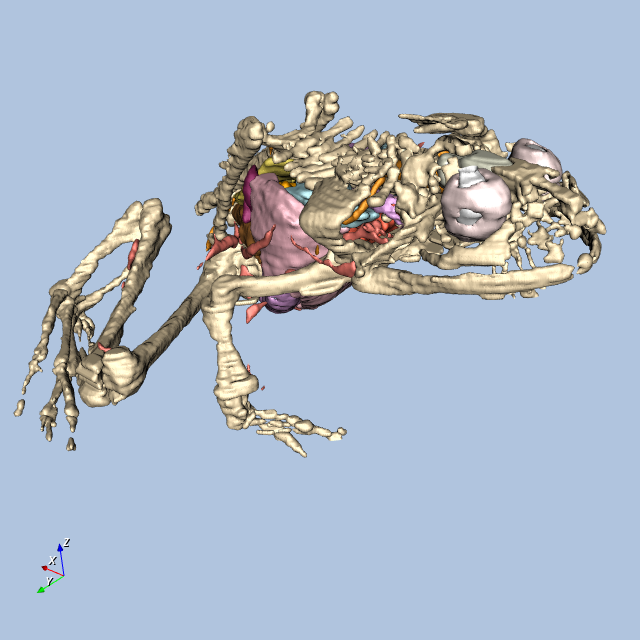
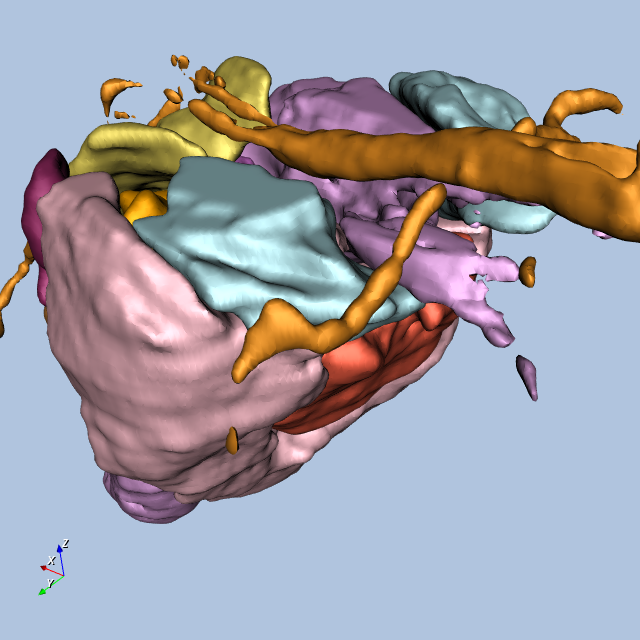
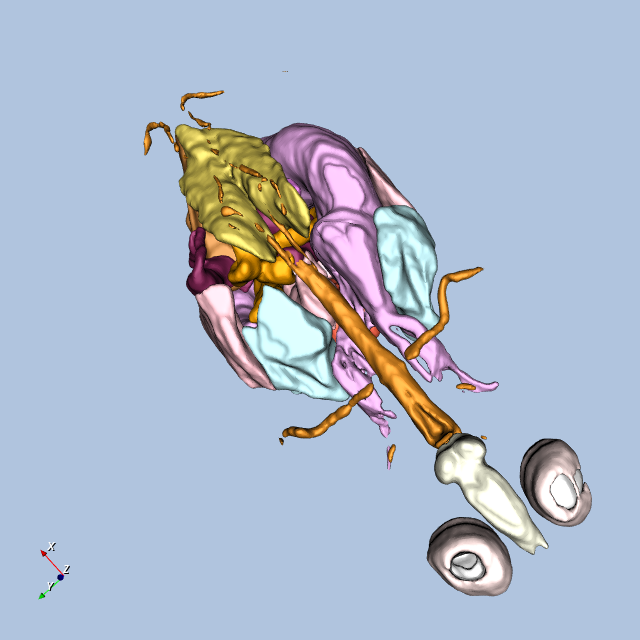
Other Frog-Related Information
The folks at Lawrence Berkeley National Laboratory have an impressive Web site that features the frog used in this example. The site describes how the frog data was obtained and also permits users to create mpeg movies of the frog. There are also other datasets available. Further details on "The Whole Frog Project" can be found at http://www-itg.lbl.gov/Frog. Also, the Stanford University Medical Media and Information Technologies (SUMMIT) group has on-going work using the Berkeley frog. They are early VTK users.
12.3 Financial Visualization¶
The application of 3D visualization techniques to financial data is relatively new. Historically, financial data has been represented using 2D plotting techniques such as line, scatter plots, bar charts, and pie charts. These techniques are especially well suited for the display of price and volume information for stocks, bonds, and mutual funds. Three-dimensional techniques are becoming more important due to the increased volume of information in recent years, and 3D graphics and visualization techniques are becoming interactive. Interactive rates mean that visualization can be applied to the day-to-day processing of data. Our belief is that this will allow deeper understanding of today's complex financial data and other more timely decisions.
In this example we go through the process of obtaining data, converting it to a form that we can use, and then using visualization techniques to view it. Some of the external software tools used in this example may be unfamiliar to you. This should not be a large concern. We have simply chosen the tools with which we are familiar. Where we have used an Awk script, you might choose to write a small C program to do the same thing. The value of the example lies in illustrating the high-level process of solving a visualization problem.
The first step is to obtain the data. We obtained our data from a public site on the World Wide Web (WWW) that archives stock prices and volumes for many publicly traded stocks. (This Web site has closed down since publication of the first edition. The data for this example are available on the CD-ROM.)
Once we have obtained the data, we convert it to a format that can be read into VTK. While VTK can read in a variety of data formats, frequently your data will not be in one of those. The data files we obtained are stored in the following format:
930830 49.375 48.812 49.250 1139.2 56.1056 930831 49.375 48.938 49.125
1360.4 66.8297 930902 49.188 48.688 48.750 1247.2 60.801 ...
Each line stores the data for one day of trading. The first number is the date, stored as the last two digits of the year, followed by a two-digit month and finally the day of the month. The next three values represent the high, low, and closing price of the stock for that day. The next value is the volume of trading in thousands of shares. The final value is the volume of trading in millions of dollars.
We used an Awk script to convert the original data format into a VTK data file. (See the VTK User's Guide for information on VTK file formats; or see VTK File Formats.) This conversion could be done using many other approaches, such as writing a C program or a Tcl script.
BEGIN {print "# vtk DataFile Version 2.0\n
Data values for stocknASCII\\n\\nDATASET POLYDATA"}
{count += 1}
{ d = $1%100}
{ m = int(($1%10000)/100)}
{ if (m == 2) d += 31}
{ if (m == 3) d += 59}
{ if (m == 4) d += 90}
{ if (m == 5) d += 120}
{ if (m == 6) d += 151}
{ if (m == 7) d += 181}
{ if (m == 8) d += 212}
{ if (m == 9) d += 243}
{ if (m == 10) d += 273}
{ if (m == 11) d+= 304}
{ if (m == 12) d += 334}
{ d = d + (int($1/10000) - 93)*365}
{dates[count] = d; prices[count] = $4; volumes[count] = $5}
END {
print "POINTS " count " float";
for (i = 1; i <= count; i++) print dates[i] " " prices[i] " 0 ";
print "\nLINES 1 " (count + 1) " " count;
for (i = 0; i \< count; i++) print i;
print "\nPOINT_DATA " count "\nSCALARS volume float";
print "LOOKUP\_TABLE default";
for (i = 1; i \<= count; i++) print volumes\[i\];
}
The above Awk script performs the conversion. Its first line outputs the required header information indicating that the file is a VTK data file containing polygonal data. It also includes a comment indicating that the data represents stock values. There are a few different VTK data formats that we could have selected. It is up to you to decide which format best suits the data you are visualizing. We have judged the polygonal format ( vtkPolyData ) as best suited for this particular stock visualization.
The next line of the Awk script creates a variable named count that keeps track of how many days worth of information is in the file. This is equivalent to the number of lines in the original data file.
The next fourteen lines convert the six digit date into a more useful format, since the original format has a number of problems. If we were to blindly use the original format and plot the data using the date as the independent variable, there would be large gaps in our plot. For example, 931231 is the last day of 1993 and 940101 is the first day of 1994. Chronologically, these two dates are sequential, but mathematically there are (940101-931231=8870 values between them. A simple solution would be to use the line number as our independent variable. This would work as long as we knew that every trading day was recorded in the data file. It would not properly handle the situation where the market was open, but for some reason data was not recorded. A better solution is to convert the dates into numerically ordered days. The preceding Awk script sets January 1, 1993, as day number one, and then numbers all the following days from there. At the end of these 14 lines the variable, d, will contain the resulting value.
The next line in our Awk script stores the converted date, closing price, and dollar volume into arrays indexed by the line number stored in the variable count. Once all the lines have been read and stored into the arrays, we write out the rest of the VTK data file. We have selected the date as our independent variable and x coordinate. The closing price we store as the y coordinate, and the z coordinate we set to zero. After indicating the number and type of points to be stored, the Awk script loops through all the points and writes them out to the VTK data file. It then writes out the line connectivity list. In this case we just connect one point to the next to form a polyline for each stock. Finally, we write out the volume information as scalar data associated with the points. Portions of the resulting VTK data file are shown below.
# vtk DataFile Version 2.0
Data values for stock
ASCII
DATASET POLYDATA
POINTS 348 float
242 49.250 0
243 49.125 0
245 48.750 0
246 48.625 0
...
LINES 1 349 348
0
1
2
3
...
POINT_DATA 348
SCALARS volume float
LOOKUP_TABLE default
1139.2
1360.4
1247.2
1745.4
Now that we have generated the VTK data file, we can start the process of creating a visualization for the stock data. To do this, we wrote a Tcl script to be used with the Tcl-based VTK executable. At a high level the script reads in the stock data, sends it through a tube filter, creates a label for it, and then creates an outline around the resulting dataset. Ideally, we would like to display multiple stocks in the same window. To facilitate this, we designed the Tcl script to use a procedure to perform operations on a per stock basis. The resulting script is listed below.
#!/usr/bin/env python
import os
import vtk
def main():
colors = vtk.vtkNamedColors()
fileNames = ['GE.vtk', 'GM.vtk', 'IBM.vtk', 'DEC.vtk']
# Set up the stocks
renderers = list()
topRenderer = vtk.vtkRenderer()
bottomRenderer = vtk.vtkRenderer()
renderers.append(topRenderer)
renderers.append(bottomRenderer)
# create the outline
apf = vtk.vtkAppendPolyData()$\index{vtkAppendPolyData!application}$
olf = vtk.vtkOutlineFilter()$\index{vtkOutlineFilter!application}$
olf.SetInputConnection(apf.GetOutputPort())
outlineMapper = vtk.vtkPolyDataMapper()
outlineMapper.SetInputConnection(olf.GetOutputPort())
outlineActor = vtk.vtkActor()
outlineActor.SetMapper(outlineMapper)
zPosition = 0.0
for fn in fileNames:
zPosition = AddStock(renderers, apf, fn,
os.path.basename((os.path.splitext(fn)[0])), zPosition)
# Setup the render window and interactor.
renderWindow = vtk.vtkRenderWindow()
renderWindow.AddRenderer(renderers[0])
renderWindow.AddRenderer(renderers[1])
renderWindowInteractor = vtk.vtkRenderWindowInteractor()
renderWindowInteractor.SetRenderWindow(renderWindow)
renderers[0].SetViewport(0.0, 0.4, 1.0, 1.0)
renderers[1].SetViewport(0.0, 0.0, 1.0, 0.4)
renderers[0].GetActiveCamera().SetViewAngle(5.0)
renderers[0].ResetCamera()
renderers[0].GetActiveCamera().Zoom(1.4)
renderers[0].ResetCameraClippingRange()
renderers[0].SetBackground(colors.GetColor3d("SteelBlue"))
renderers[1].GetActiveCamera().SetViewUp(0, 0, -1)
renderers[1].GetActiveCamera().SetPosition(0, 1, 0)
renderers[1].GetActiveCamera().SetViewAngle(5.0)
renderers[1].ResetCamera()
renderers[1].GetActiveCamera().Zoom(2.2)
renderers[1].ResetCameraClippingRange()
renderers[1].SetBackground(colors.GetColor3d("LightSteelBlue"))
renderers[0].AddActor(outlineActor)
renderers[1].AddActor(outlineActor)
renderWindow.SetSize(500, 800)
renderWindow.Render()
renderWindowInteractor.Start()
def AddStock(renderers, apf, filename, name, zPosition):
# Read the data
PolyDataRead = vtk.vtkPolyDataReader()
PolyDataRead.SetFileName(filename)
PolyDataRead.Update()
TubeFilter = vtk.vtkTubeFilter()$\index{vtkTubeFilter!application}$
TubeFilter.SetInputConnection(PolyDataRead.GetOutputPort())
TubeFilter.SetNumberOfSides(8)
TubeFilter.SetRadius(0.5)
TubeFilter.SetRadiusFactor(10000)
Transform = vtk.vtkTransform()$\index{vtkTransform!application}$
Transform.Translate(0, 0, zPosition)
Transform.Scale(0.15, 1, 1)
TransformFilter = vtk.vtkTransformPolyDataFilter()
TransformFilter.SetInputConnection(TubeFilter.GetOutputPort())
TransformFilter.SetTransform(Transform)
# Create the labels.
TextSrc = vtk.vtkVectorText()$\index{vtkVectorText!application}$
TextSrc.SetText(name)
numberOfPoints = PolyDataRead.GetOutput().GetNumberOfPoints()
nameIndex = int((numberOfPoints - 1) * 0.8)
nameLocation = PolyDataRead.GetOutput().GetPoint(nameIndex)
x = nameLocation[0] * 0.15
y = nameLocation[1] + 5.0
z = zPosition
apf.AddInputData(TransformFilter.GetOutput())
for r in range(0, len(renderers)):
LabelMapper = vtk.vtkPolyDataMapper()
LabelMapper.SetInputConnection(TextSrc.GetOutputPort())
LabelActor = vtk.vtkFollower()$\index{vtkFollower!example}$
LabelActor.SetMapper(LabelMapper)
LabelActor.SetPosition(x, y, z)
LabelActor.SetScale(2, 2, 2)
LabelActor.SetOrigin(TextSrc.GetOutput().GetCenter())
# Increment zPosition.
zPosition += 8.0
StockMapper = vtk.vtkPolyDataMapper()
StockMapper.SetInputConnection(TransformFilter.GetOutputPort())
StockMapper.SetScalarRange(0, 8000)
StockActor = vtk.vtkActor()
StockActor.SetMapper(StockMapper)
renderers[r].AddActor(StockActor)
renderers[r].AddActor(LabelActor)
LabelActor.SetCamera(renderers[r].GetActiveCamera())
return zPosition
if __name__ == '__main__':
main()
The first part of this script consists of the standard procedure for renderer and interactor creation that can be found in almost all of the VTK Tcl scripts. The next section creates the objects necessary for drawing an outline around all of the stock data. A vtkAppendPolyData filter is used to append all of the stock data together. This is then sent through a vtkOutlineFilter to create a bounding box around the data. A mapper and actor are created to display the rIn the next part of this script, we define the procedure to add stock data to this visualization. The procedure takes five arguments: the name of the stock, the label we want displayed, and the x, y, z coordinates defining where to position the label. The first line of the procedure indicates that the variable ren1 should be visible to this procedure. By default the procedure can only access its own local variables. Next, we create the label using a vtkTextSource, vtkPolyDataMapper, and vtkFollower. The names of these objects are all prepended with the variable " $prefix. " so that the instance names will be unique. An instance of vtkFollower is used instead of the usual vtkActor, because we always want the text to be right-side up and facing the camera. The vtkFollower class provides this functionality. The remaining lines position and scale the label appropriately. We set the origin of the label to the center of its data. This insures that the follower will rotate about its center point.
The next group of lines creates the required objects to read in the data, pass it through a tube filter and a transform filter, and finally display the result. The tube filter uses the scalar data (stock volume in this example) to determine the radius of the tube. The mapper also uses the scalar data to determine the coloring of the tube. The transform filter uses a transform object to set the stock's position based on the value of the variable zpos. For each stock, we will increment zpos by 10, effectively shifting the next stock over 10 units from the current stock. This prevents the stocks from being stacked on top of each other. We also use the transform to compress the x-axis to make the data easier to view. Next, we add this stock as an input to the append filter and add the actors and followers to the renderer. The last line of the procedure sets the follower's camera to be the active camera of the renderer.
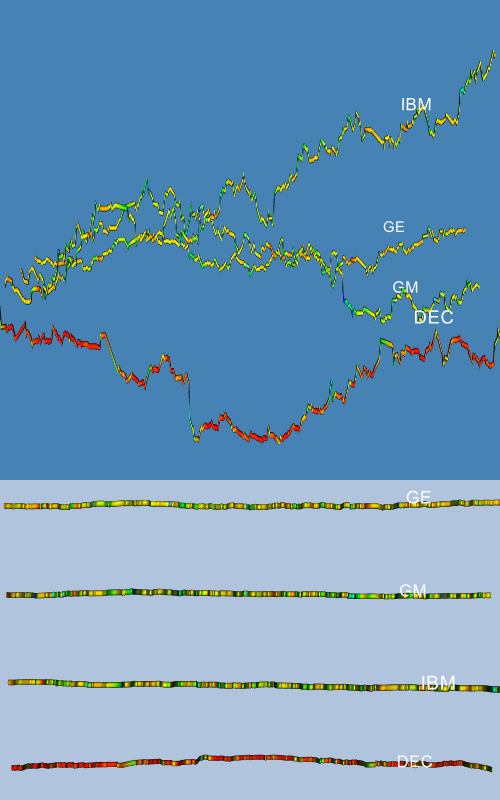
Back in the main body of the Tcl script, we invoke the AddStock procedure four times with four different stocks. Finally, we add the outline actor and customize the renderer and camera to four different stocks. Finally, we add the outline actor and customize the renderer and camera to produce a nice initial view. Two different views of the result are displayed in Figure 12-10. The top image shows a history of stock closing prices for our four stocks. The color and width of these lines correspond to the volume of the stock on that day. The lower image more clearly illustrates the changes in stock volume by looking at the data from above.
Figure 12-10 Two views from the stock visualization script. The top shows closing price over time; the bottom shows volume over time ( stocks.tcl ).
A legitimate complaint with Figure 12-10 is that the changing width of the tube makes it more difficult to see the true shape of the price verses the time curve. We can solve this problem by using a ribbon filter followed by a linear extrusion filter, instead of the tube filter. The ribbon filter will create a ribbon whose width will vary in proportion to the scalar value of the data. We then use the linear extrusion filter to extrude this ribbon along the y-axis so that it has a constant thickness. The resulting views are shown in Figure 12-11.
12.4 Implicit Modelling¶
The Visualization Toolkit has some useful geometric modelling capabilities. One of the most powerful features is implicit modelling. In this example we show how to use polygonal descriptions of objects and create "blobby" models of them using the implicit modelling objects in VTK. This example generates a logo for the Visualization Toolkit from polygonal representations of the letters v, t, and k.
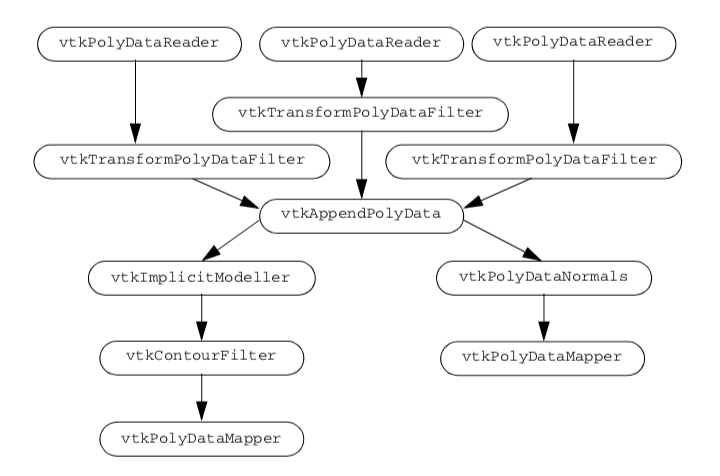
We create three separate visualization pipelines, one for each letter. Figure 12-12 shows the visualization pipeline. As is common in VTK applications, we design a pipeline and fill in the details of the instance variables just before we render. We pass the letters through a vtkTransformPolyDataFilter to position them relative to each other. Then we combine all of the polygons from the transformed letters into one polygon dataset using the vtkAppendPolyData filter. The vtkImplicitModeller creates a volume dataset of dimension 643 with each voxel containing a scalar value that is the distance to the nearest polygon. Recall from "Implicit Modelling" in Chapter 6 that the implicit modelling algorithm lets us specify the region of influence of each polygon. Here we specify this using the SetMaximumDistance() method of the vtkImplicitModeller. By restricting the region of influence, we can significantly improve performance of the implicit modelling algorithm. Then we use vtkContourFilter to extract an isosurface that approximates a distance of 1.0 from each polygon. We create two actors: one for the blobby logo and one for the original polygon letters. Notice that both actors share the polygon data created by vtkAppendPolyData. Because of the nature of the VTK visualization pipeline (see "Implicit Execution" in Chapter 4), the appended data will only be created once by the portion of the pipeline that is executed first. As a final touch, we move the polygonal logo in front of the blobby logo. Now we will go through the example in detail.
First, we read the geometry files that contain polygonal models of each letter in the logo. The data is in VTK polygonal format, so we use vtkPolyDataReader .
vtkPolyDataReader *letterV = vtkPolyDataReader::New();
letterV->SetFileName ("v.vtk");
vtkPolyDataReader *letterT = vtkPolyDataReader::New();
letterT->SetFileName ("t.vtk");
vtkPolyDataReader *letterK = vtkPolyDataReader::New();
letterK->SetFileName ("k.vtk");
We want to transform each letter into its appropriate location and orientation within the logo. We create the transform filters here, but defer specifying the location and orientation until later in the program.
vtkTransform *VTransform = vtkTransform::New();
vtkTransformPolyDataFilter *VTransformFilter =
vtkTransformPolyDataFilter::New();
VTransformFilter->SetInputConnection (letterV->GetOutputPort());
VTransformFilter->SetTransform (VTransform);
vtkTransform *TTransform = vtkTransform::New();
vtkTransformPolyDataFilter *TTransformFilter =
vtkTransformPolyDataFilter::New();
TTransformFilter->SetInputConnection (letterT->GetOutputPort());
TTransformFilter->SetTransform (TTransform);
vtkTransform *KTransform = vtkTransform::New();
vtkTransformPolyDataFilter *KTransformFilter =
vtkTransformPolyDataFilter::New();
KTransformFilter->SetInputConnection (letterK->GetOutputPort());
KTransformFilter->SetTransform (KTransform);
We collect all of the transformed letters into one set of polygons by using an instance of the class vtkAppendPolyData.
vtkAppendPolyData *appendAll = vtkAppendPolyData::New();
appendAll->AddInputConnection (VTransformFilter->GetOutputPort());
appendAll->AddInputConnection (TTransformFilter->GetOutputPort());
appendAll->AddInputConnection (KTransformFilter->GetOutputPort());
Since the geometry for each letter did not have surface normals, we add them here. We use vtkPolyDataNormals. Then we complete this portion of the pipeline by creating a mapper and an actor.
// create normals
vtkPolyDataNormals *logoNormals = vtkPolyDataNormals::New();
logoNormals->SetInputConnection (appendAll->GetOutputPort());
logoNormals->SetFeatureAngle (60);
// map to rendering primitives
vtkPolyDataMapper *logoMapper = vtkPolyDataMapper::New();
logoMapper->SetInputConnection (logoNormals->GetOutputPort());
// now an actor
vtkActor *logo = vtkActor::New();
logo->SetMapper (logoMapper);
We create the blobby logo with the implicit modeller, and then extract the logo with vtkContourFilter. The pipeline is completed by creating a mapper and an actor.
// now create an implicit model of the letters vtkImplicitModeller
*blobbyLogoImp = vtkImplicitModeller::New();
blobbyLogoImp->SetInputConnection (appendAll->GetOutputPort());
blobbyLogoImp->SetMaximumDistance (.075);
blobbyLogoImp->SetSampleDimensions (64,64,64);
blobbyLogoImp->SetAdjustDistance (0.05);
// extract an iso surface
vtkContourFilter *blobbyLogoIso = vtkContourFilter::New();
blobbyLogoIso->SetInputConnection (blobbyLogoImp->GetOutputPort());
blobbyLogoIso->SetValue (1, 1.5);
// map to rendering primitives
vtkPolyDataMapper *blobbyLogoMapper = vtkPolyDataMapper::New();
blobbyLogoMapper->SetInputConnection (
blobbyLogoIso->GetOutputPort());
blobbyLogoMapper->ScalarVisibilityOff ();
// now an actor
vtkActor *blobbyLogo = vtkActor::New();
blobbyLogo->SetMapper(blobbyLogoMapper);
blobbyLogo->SetProperty (banana);
To improve the look of our resulting visualization, we define a couple of organic colors. Softer colors show up better on some electronic media (e.g., VHS video tape) and are pleasing to the eye.
vtkProperty *tomato = vtkProperty::New();
tomato->SetDiffuseColor(1,.3882, .2784);
tomato->SetSpecular(.3);
tomato->SetSpecularPower(20);
vtkProperty *banana = vtkProperty::New();
banana->SetDiffuseColor(.89, .81, .34);
banana->SetDiffuse (.7);
banana->SetSpecular(.4);
banana->SetSpecularPower(20);
These colors are then assigned to the appropriate actors.

logo->SetProperty(tomato);
blobbyLogo->SetProperty(banana);
And finally, we position the letters in the logo and move the polygonal logo out in front of the blobby logo by modifying the actor's position.
VTransform->Translate (-16,0,12.5);
VTransform->RotateY (40);
KTransform->Translate (14, 0, 0);
KTransform->RotateY (-40);
// move the polygonal letters to the front
logo->SetPosition(0,0,6);
An image made from the techniques described in this section is shown in Figure 12-13 Note that the image on the left has been augmented with a texture map.
12.5 Computational Fluid Dynamics¶
Computational Fluid Dynamics (CFD) visualization poses a challenge to any visualization toolkit. CFD studies the flow of fluids in and around complex structures. Often, large amounts of super-computer time is used to derive scalar and vector data in the flow field. Since CFD computations produce multiple scalar and vector data types, we will apply many of the tools described in this book. The challenge is to combine multiple representations into meaningful visualizations that extract information without overwhelming the user.
There are a number of techniques we can use when we first look at the complex data presented by CFD applications. Since we need to apply several algorithms to the data, and since there will be many parameter changes for these algorithms, we suggest using the Tcl interpreter rather than C++ code. Our strategy for visualizing this CFD data includes the following:
-
Display the computational grid. The analyst carefully constructed the finite difference grid to have a higher density in regions where rapid changes occur in the flow variables. We will display the grid in wireframe so we can see the computational cells.
-
Display the scalar fields on the computational grid. This will give us an overview of where the scalar data is changing. We will experiment with the extents of the grid extraction to focus on interesting areas.
-
Explore the vector field by seeding streamlines with a spherical cloud of points. Move the sphere through areas of rapidly changing velocity.
-
Try using the computational grid itself as seeds for the streamlines. Of course we will have to restrict the extent of the grid you use for this purpose. Using the grid, we will be able to place more seeds in regions where the analyst expected more action.
For this case study, we use a dataset from NASA called the LOx Post. It simulates the flow of liquid oxygen across a flat plate with a cylindrical post perpendicular to the flow [Rogers86]. This analysis models the flow in a rocket engine. The post promotes mixing of the liquid oxygen.
We start by exploring the scalar and vector fields in the data. By calculating the magnitude of the velocity vectors, we derive a scalar field. This study has a particularly interesting vector field around the post. We seed the field with multiple starting points (using points arranged along a curve, referred to as a rake) and experiment with parameters for the streamlines. Streampolygons are particularly appropriate here and do a nice job of showing the flow downstream from the post. We animate the streamline creation by moving the seeding line or rake back and forth behind the post.
Following our own advice, we first display the computational grid. The following Tcl code produced the right image of Figure 12-14.
# read data
vtkPLOT3DReader pl3d
pl3d SetXYZFileName "$env(VTK_TEXTBOOK_DATA)/postxyz.bin"
pl3d SetQFileName "$env(VTK_TEXTBOOK_DATA)/postq.bin"
pl3d IBlankingOn
pl3d Update
# computational planes: the floor
vtkStructuredGridGeometryFilter floorComp
floorComp SetExtent 0 37 0 75 0 0
floorComp SetInputConnection [pl3d GetOutputPort]
vtkPolyDataMapper floorMapper
floorMapper SetInputConnection [floorComp GetOutputPort]
floorMapper ScalarVisibilityOff
vtkActor floorActor
floorActor SetMapper floorMapper
[floorActor GetProperty] SetColor 0 0 0
[floorActor GetProperty] SetRepresentationToWireframe
## the post
vtkStructuredGridGeometryFilter postComp
postComp SetExtent 10 10 0 75 0 37
postComp SetInputConnection [pl3d GetOutputPort]
vtkPolyDataMapper postMapper
postMapper SetInputConnection [postComp GetOutputPort]
postMapper ScalarVisibilityOff
vtkActor postActor
postActor SetMapper postMapper
[postActor GetProperty] SetColor 0 0 0
[postActor GetProperty] SetRepresentationToWireframe
# plane upstream of the flow
vtkStructuredGridGeometryFilter fanComp
fanComp SetExtent 0 37 38 38 0 37
fanComp SetInputConnection [pl3d GetOutputPort]
vtkPolyDataMapper fanMapper
fanMapper SetInputConnection [fanComp GetOutputPort]
fanMapper ScalarVisibilityOff
vtkActor fanActor
fanActor SetMapper fanMapper
[fanActor GetProperty] SetColor 0 0 0
[fanActor GetProperty] SetRepresentationToWireframe
# outline
vtkStructuredGridOutlineFilter outline
outline SetInputConnection [pl3d GetOutputPor]
vtkPolyDataMapper outlineMapper
outlineMapper SetInputConnection [outline GetOutputPort]
vtkActor outlineActor
outlineActor SetMapper outlineMapper
[outlineActor GetProperty] SetColor 0 0 0
# Create graphics stuff
vtkRenderer ren1
vtkRenderWindow renWin
renWin AddRenderer ren1
vtkRenderWindowInteractor iren
iren SetRenderWindow renWin
# Add the actors to the renderer, set the background and size
#
ren1 AddActor outlineActor
ren1 AddActor floorActor
ren1 AddActor postActor
ren1 AddActor fanActor
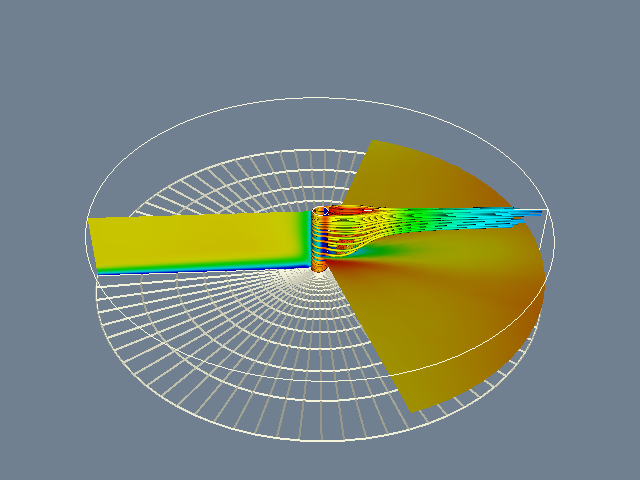
To display the scalar field using color mapping, we must change the actor's representation from wireframe to surface, turn on scalar visibility for each vtkPolyDataMapper, set each mapper's scalar range, and render again, producing the right image of Figure 12-14.
postActor SetRepresentationToSurface
fanActor SetRepresentationToSurface
floorActor SetRepresentationToSurface
postMapper ScalarVisibilityOn
postMapper SetScalarRange [[pl3d GetOutput] GetScalarRange]
fanMapper ScalarVisibilityOn
fanMapper SetScalarRange [[pl3d GetOutput] GetScalarRange]
floorMapper ScalarVisibilityOn
floorMapper SetScalarRange [[pl3d GetOutput] GetScalarRange]
Now, we explore the vector field using vtkPointSource. Recall that this object generates a random cloud of points around a spherical center point. We will use this cloud of points to generate stream-lines. We place the center of the cloud near the post since this is where the velocity seems to be changing most rapidly. During this exploration, we use streamlines rather than streamtubes for reasons of efficiency. The Tcl code is as follows.
# spherical seed points
vtkPointSource rake
rake SetCenter -0.74 0 0.3
rake SetNumberOfPoints 10
vtkStreamLine streamers
streamers SetInputConnection [pl3d GetOutputPort]
streamers SetSourceConnection [rake GetOutputPort]
streamers SetMaximumPropagationTime 250
streamers SpeedScalarsOn
streamers SetIntegrationStepLength .2
streamers SetStepLength .25
vtkPolyDataMapper mapTubes
mapTubes SetInputConnection [streamers GetOutputPort]
eval mapTubes SetScalarRange [[pl3d GetOutput] GetScalarRange]
vtkActor tubesActor
tubesActor SetMapper mapTubes
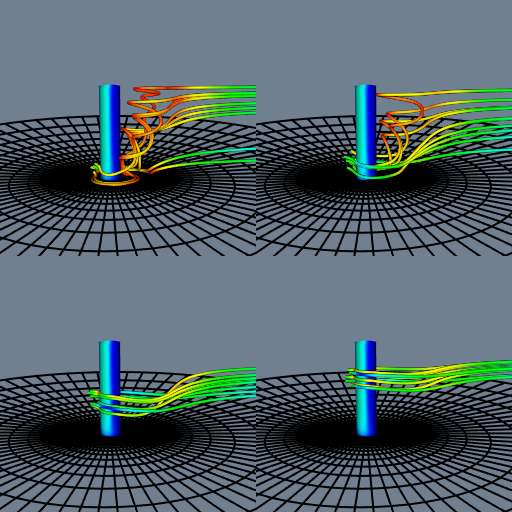
Figure 12-15 shows streamlines seeded from four locations along the post. Notice how the structure of the flow begins to emerge as the starting positions for the streamlines are moved up and down in front of the post. This is particularly true if we do this interactively; the mind assembles the behavior of the streamlines into a global understanding of the flow field.
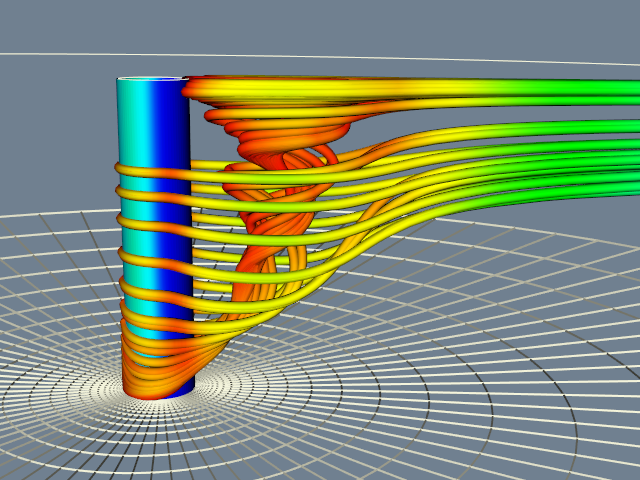
For a final example, we use the computational grid to seed streamlines and then generate streamtubes as is shown in Figure 12-16. A nice feature of this approach is that we generate more streamlines in regions where the analyst constructed a denser grid. The only change we need to make is to replace the rake from the sphere source with a portion of the grid geometry.
vtkStructuredGridGeometryFilter seedsComp
seedsComp SetExtent 10 10 37 39 1 35
seedsComp SetInput [pl3d GetOutput]
streamers SetSourceConnection [seedsComp GetOutputPort]
# create tubes
vtkTubeFilter tubes
tubes SetInputConnection [streamers GetOutputPort]
tubes SetNumberOfSides 8
tubes SetRadius .08
tubes SetVaryRadiusOff
# change input to streamtubes
mapTubes SetInputConnection [tubes GetOutputPort]
There are a number of other methods we could use to visualize this data. A 3D widget such as the vtkLineWidget could be used to seed the streamlines interactively (see "3D Widgets and User Interaction" in Chapter 7). As we saw in "Point Probe" in Chapter 8, probing the data for numerical values is a valuable technique. In particular, if the probe is a line we can use it in combination with vtkXYPlotActor to graph the variation of data value along the line. Another useful visualization would be to identify regions of vorticity. We could use Equation9-12 in conjunction with an isocontouring algorithm (e.g., vtkContourFilter ) to creates isosurfaces of large helical-density.
12.6 Finite Element Analysis¶
Finite element analysis is a widely used numerical technique for finding solutions of partial differential equations. Applications of finite element analysis include linear and nonlinear structural, thermal, dynamic, electromagnetic, and flow analysis. In this application we will visualize the results of a blow molding process.
In the extrusion blow molding process, a material is extruded through an annular die to form a hollow cylinder. This cylinder is called a parison. Two mold halves are then closed on the parison, while at the same time the parison is inflated with air. Some of the parison material remains within the mold while some becomes waste material. The material is typically a polymer plastic softened with heat, but blow molding has been used to form metal parts. Plastic bottles are often manufactured using a blow molding process.
Designing the parison die and molds is not easy. Improper design results in large variations in the wall thickness. In some cases the part may fail in thin-walled regions. As a result, analysis tools based on finite element techniques have been developed to assist in the design of molds and dies.
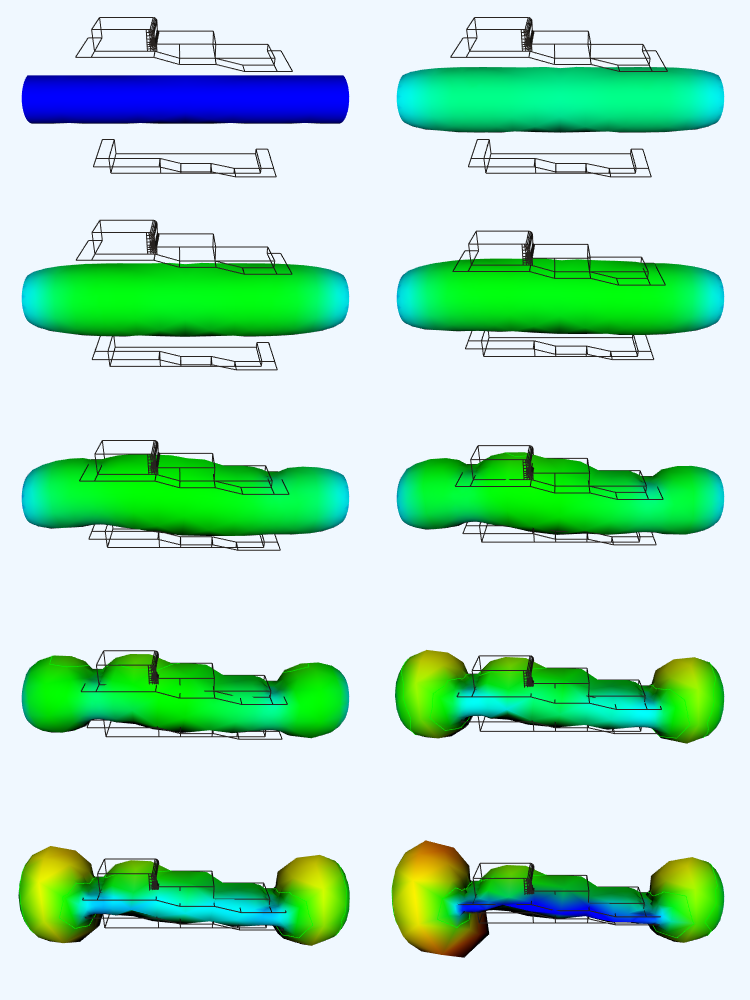
The results of one such analysis are shown in Figure 12-17. The polymer was molded using an isothermal, nonlinear-elastic, incompressible (rubber-like) material. Triangular membrane finite elements were used to model the parison, while a combination of triangular and quadrilateral finite elements were used to model the mold. The mold surface is assumed to be rigid, and the parison is assumed to attach to the mold upon contact. Thus the thinning of the parison is controlled by its stretching during inflation and the sequence in which it contacts the mold.
Figure 12-17 illustrates 10 steps of one analysis. The color of the parison indicates its thickness. Using a rainbow scale, red areas are thinnest while blue regions are thickest. Our visualization shows clearly one problem with the analysis technique we are using. Note that while the nodes (i.e., points) of the finite element mesh are prevented from passing through the mold, the interior of the triangular elements are not. This is apparent from the occlusion of the mold wireframe by the parison mesh.
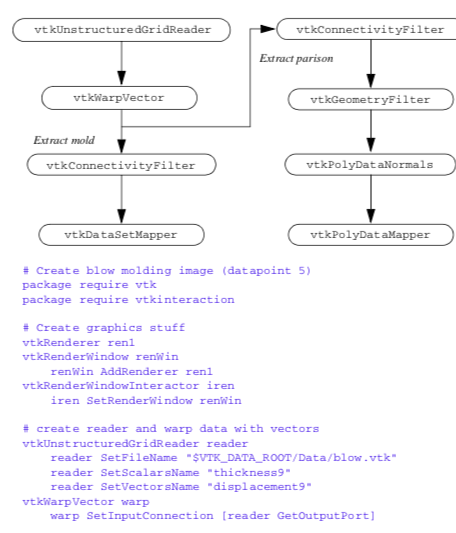
To generate these images, we used a Tcl script shown in Figure 12-18 and Figure 12-19. The input data is in VTK format, so a vtkUnstructuredGridReader was used as a source object. The mesh displacement is accomplished using an instance of vtkWarpVector. At this point the pipeline splits. We wish to treat the mold and parison differently (different properties such as wireframe versus surface), but the data for both mold and parison is combined. Fortunately, we can easily separate the data using two instances of class vtkConnectivityFilter. One filter extracts the parison, while the other extracts both parts of the mold. Finally, to achieve a smooth surface appearance on the parison, we use a vtkPolyDataNormals filter. In order to use this filter, we have to convert the data type from vtkUnstructuredGrid (output of vtkConnectivityFilter ) to type vtkPolyData. The filter vtkGeometryFilter does this nicely.
12.7 Algorithm Visualization¶
Visualization can be used to display algorithms and data structures. Representing this information often requires creative work on the part of the application programmer. For example, Robertson et al. [Robertson91] have shown 3D techniques for visualizing directory structures and navigating through them. Their approach involves building three dimensional models (the so-called "cone trees") to represent files, directories, and associations between files and directories. Similar approaches can be used to visualize stacks, queues, linked lists, trees, and other data structures.
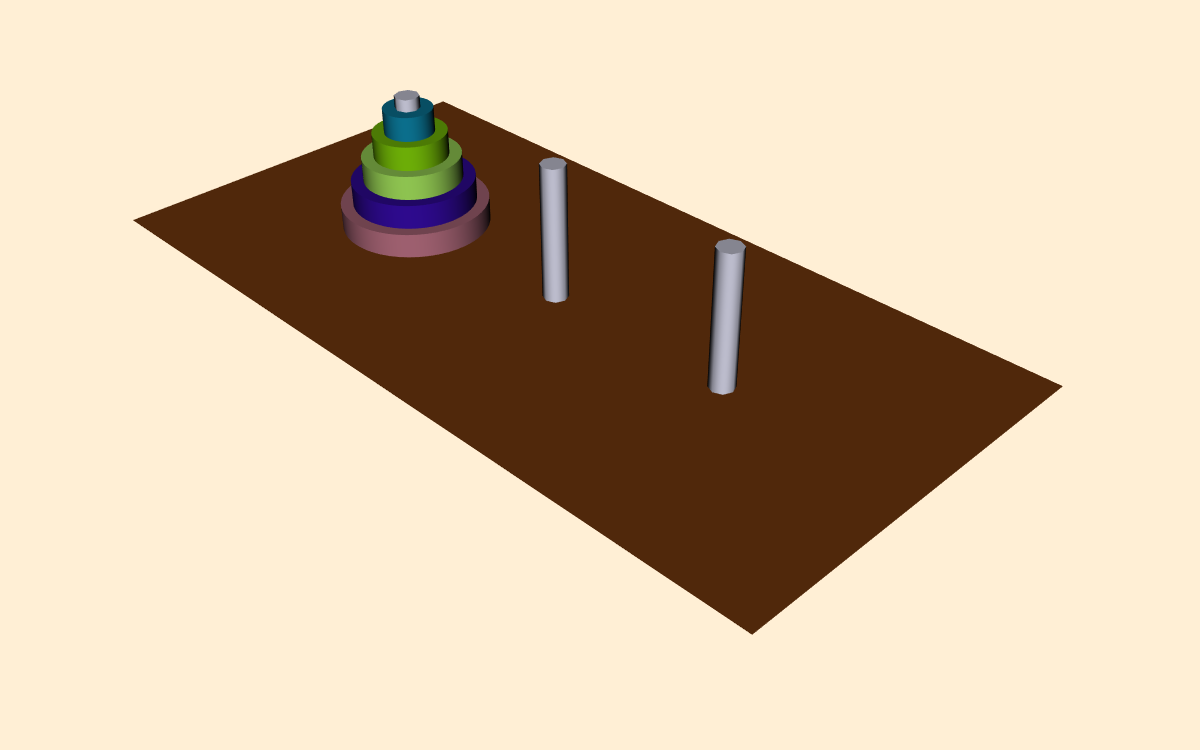
In this example we will visualize the operation of the recursive Towers of Hanoi puzzle. In this puzzle there are three pegs ( Figure 12-20 ). In the initial position there are one or more disks (or pucks) of varying diameter on the pegs. The disks are sorted according to disk diameter, so that the largest disk is on the bottom, followed by the next largest, and so on. The goal of the puzzle is to extract mold from mesh using connectivity vtkConnectivityFilter move the disks from one peg to another, moving the disks one at a time, and never placing a larger disk on top of a smaller disk.

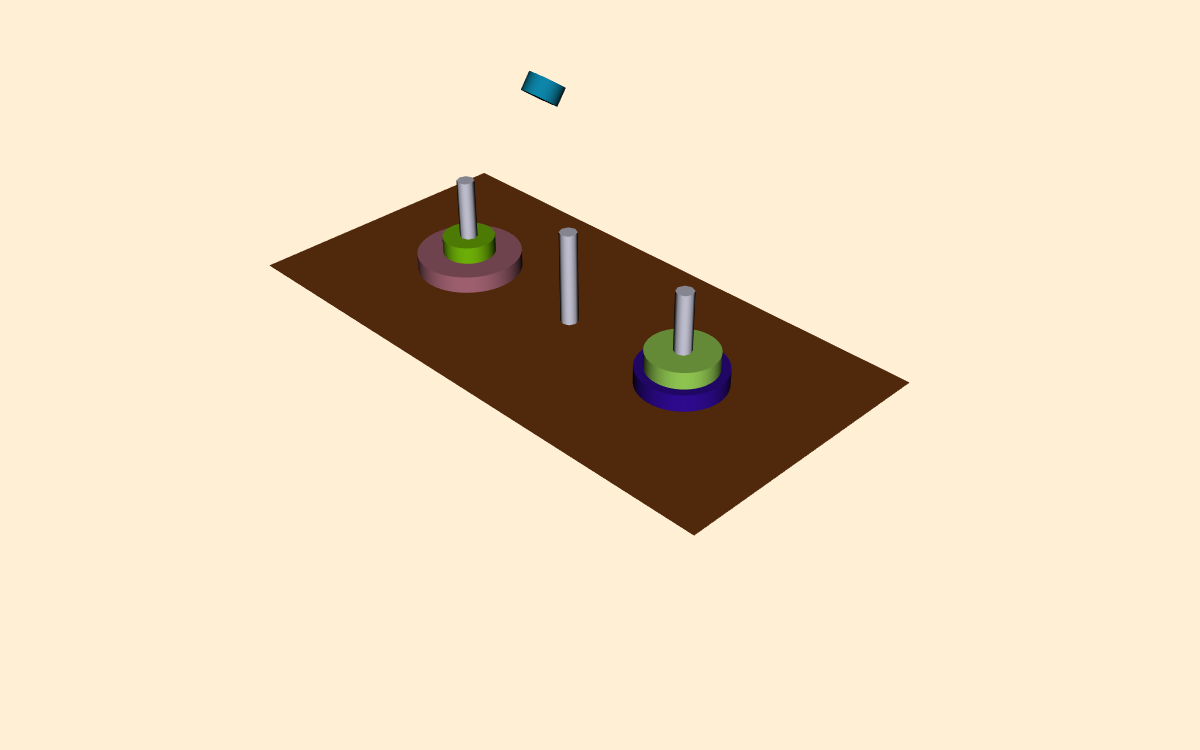
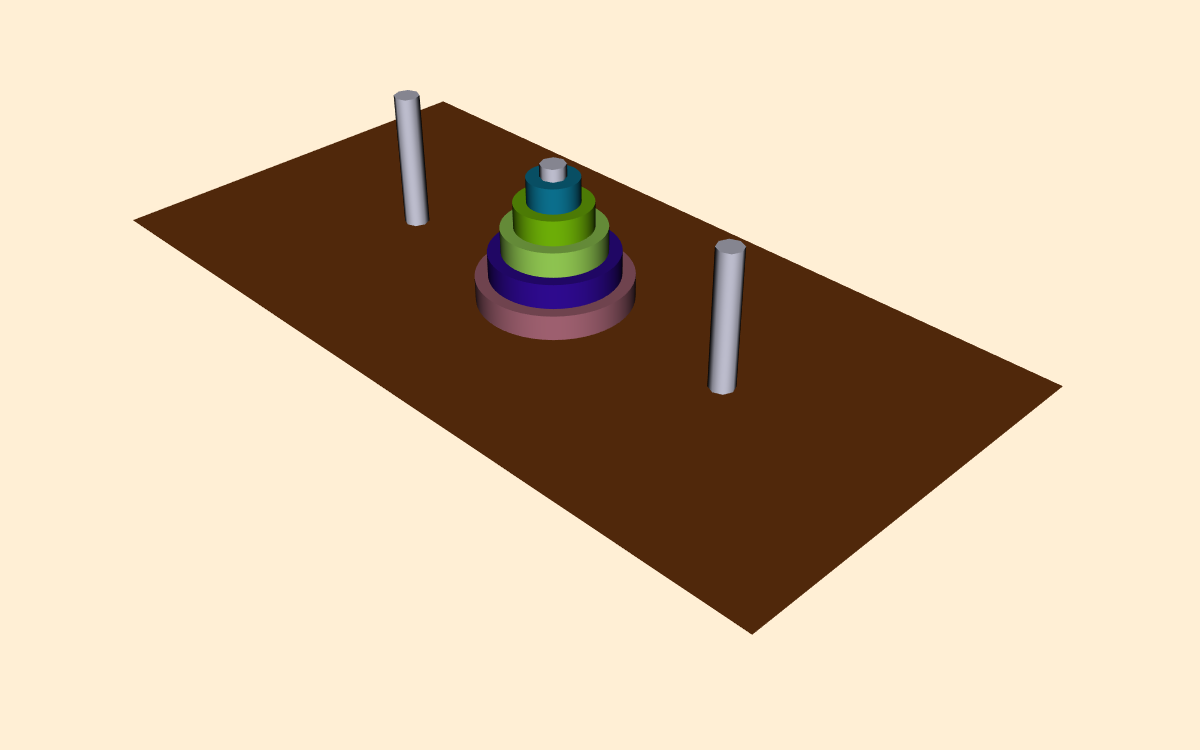


The classical solution to this puzzle is based on a divide-and-conquer approach [AhoHopUll83]. The problem of moving n disks from the initial peg to the second peg can be thought of as solving two subproblems of size n--1. First move n--1 disks from the initial peg to the third peg. Then move the nth disk to the second peg. Finally, move the n--1 disks on the third peg back to the second peg.
The solution to this problem can be elegantly implemented using recursion. We have shown portions of the C++ code in Figure 12-21 and Figure 12-22. In the first part of the solution (which is not shown in Figure 12-21 ) the table top, pegs, and disks are created using the two classes vtkPlaneSource and vtkCylinderSource. The function Hanoi() is then called to begin the recursion. The routine MovePuck() is responsible for moving a disk from one peg to another. It has been jazzed up to move the disk in small, user-specified increments, and to flip the disc over as it moves from one peg to the next. This gives a pleasing visual effect and adds the element of fun to the visualization.
Because of the clear relationship between algorithm and physical reality, the Towers of Hanoi puzzle is relatively easy to visualize. A major challenge facing visualization researchers is to visualize more abstract information, such as information on the Internet, the structure of documents, or the effectiveness of advertising/entertainment in large market segments. This type of visualization, known as information visualization, is likely to emerge in the future as an important research challenge.
12.8 Chapter Summary¶
This chapter presented several case studies covering a variety of visualization techniques. The examples used different data representations including polygonal data, volumes, structured grids, and unstructured grids. Both C++ and Tcl code was used to implement the case studies.
Medical imaging is a demanding application area due to the size of the input data. Three-dimensional visualization of anatomy is generally regarded by radiologists as a communication tool for referring physicians and surgeons. Medical datasets are typically image data---volumes or layered stacks of 2D images that form volumes. Common visualization tools for medical imaging include isosurfaces, cut planes, and image display on volume slices.
Next, we presented an example that applied 3D visualization techniques to financial data. In this case study, we began by showing how to import data from an external source. We applied tube filters to the data and varied the width of the tube to show the volume of stock trading. We saw how different views can be used to present different pieces of information. In this case, we saw that by viewing the visualization from the front, we saw a conventional price display. Then, by viewing the visualization from above, we saw trade volume.
In the modelling case study we showed how to use polygonal models and the implicit modelling facilities in VTK to create a stylistic logo. The final model was created by extracting an isosurface at a user-selected offset.
Computational fluid dynamics analysts frequently employ structured grid data. We examined some strategies for exploring the scalar and vector fields. The computational grid created by the analyst serves as a starting point for analyzing the data. We displayed geometry extracted from the finite difference grid, scalar color mapping, and streamlines and streamtubes to investigate the data.
In the finite element case study, we looked at unstructured grids used in a simulation of a blow molding process. We displayed the deformation of the geometry using displacement plots, and represented the material thickness using color mapping. We saw how we can create simple animations by generating a sequence of images.
We concluded the case studies by visualizing the Towers of Hanoi algorithm. Here we showed how to combine the procedural power of C++ with the visualization capabilities in VTK. We saw how visualization often requires our creative resources to cast data structures and information into visual form.
12.9 Bibliographic Notes¶
The case studies presented in the chapter rely on having interesting data to visualize. Sometimes the hardest part of practicing visualizing is finding relevant data. The Internet is a tremendous resource for this task. Paul Gilster [Gilster94] has written an excellent introduction to many of the tools for accessing information on the Internet. There are many more books available on this subject in the local bookstore.
In the stock case study we used a programming tool called AWK to convert our data into a form suitable for VTK. More information on AWK can be found in The AWK Programming Language [Aho88]. Another popular text processing languages is Perl [Perl95].
If you would like to know more about information visualization you can start with the references listed here [Becker95] [Ding90] [Eick93] [Feiner88] [Johnson91] [Robertson91]. This is a relatively new field but will certainly grow in the near future.
12.10 References¶
[Aho88] A. V. Aho, B. W. Kernighan, and P. J. Weinberger. The AWK Programming Language. AddisonWesley, Reading, MA, 1988.
[AhoHopUll83] A. V. Aho, J. E. Hopcroft, and J. D. Ullman. Data Structures and Algorithm s. AddisonWesley, Reading, MA, 1983.
[Becker95] R. A. Becker, S. G. Eick, and A. R. Wilks. "Visualizing Network Data." IEEE Transactions on Visualization and Graphics. 1(1):16-28,1995.
[deLorenzi93] H. G. deLorenzi and C. A. Taylor. "The Role of Process Parameters in Blow Molding and Correlation of 3-D Finite Element Analysis with Experiment." International Polymer Processing. 3(4):365-374, 1993.
[Ding90] C. Ding and P. Mateti. "A Framework for the Automated Drawing of Data Structure Diagrams." IEEE Transactions on Software Engineering. 16(5):543-557, May 1990.
[Eick93] S. G. Eick and G. J. Wills. "Navigating Large Networks with Hierarchies." In Proceedings of Visualization '93. pp. 204-210, IEEE Computer Society Press, Los Alamitos, CA, October 1993.
[Feiner88] S. Feiner. "Seeing the Forest for the Trees: Hierarchical Displays of Hypertext Structures." In Conference on Office Information Systems. Palo Alto, CA, 1988.
[Gilster94] P. Gilster. Finding It on the Internet: The Essential Guide to Archie, Veronica, Gopher, WAIS, WWW (including Mosaic), and Other Search and Browsing Tools. John Wiley & Sons, Inc., 1994.
[Johnson91] B. Johnson and B. Shneiderman. "Tree-Maps: A Space-Filling Approach to the Visualization of Hierarchical Information Structure s." In Proceedings of Visualization '91. pp. 284-291, IEEE Computer Society Press, Los Alamitos, CA, October 1991.
[Perl95] D. Till. Teach Yourself Perl in 21 Days. Sams Publishing, Indianapolis, Indiana, 1995.
[Robertson91] G. G. Robertson, J. D. Mackinlay, and S. K. Card. "Cone Trees: Animated 3D Visualizations of Hierarchical Information." In Proceedings of ACM CHI '91 Conference on Human Factors in Computing Systems. pp. 189-194, 1991.
[Rogers86] S. E. Rogers, D. Kwak, and U. K. Kaul, "A Numerical Study of Three-Dimensional Incompressible Flow Around Multiple Post." in Proceedings of AIAA Aerospace Sciences Conference. vol. AIAA Paper 86-0353. Reno, Nevada, 1986.
12.11 Exercises¶
12.1 The medical example did nothing to transform the original data into a standard coordinate system. Many medical systems use RAS coordinates. R is right/left, A is anterior/posterior and S is Superior/Inferior. This is the patient coordinate system. Discuss and compare the following alternatives for transforming volume data into RAS coordinates.
a) vtkActor transformation methods.
c) Reader transformations.
12.2 Modify the last example found in the medical application ( Medical3.cxx ) to use vtkImageDataGeometryFilter instead of vtkImageActor. Compare the performance of using geometry with using texture. How does the performance change as the resolution of the volume data changes?
12.3 Modify the last medical example ( Medical3.cxx ) to use v tkTexture and vtkPlaneSource instead of vtkImageActor.
12.4 Change the medical case study to use dividing cubes for the skin surface.
12.5 Combine the two scripts frogSegmentation.tcl and marchingFrog.tcl into one script that will handle either segmented or grayscale files. What other parameters and pipeline components might be useful in general for this application?
12.6 Create polygonal / line stroked models of your initials and build your own logo. Experiment with different transformations.
12.7 Enhance the appearance of Towers of Hanoi visualization.
a) Texture map the disks, base plane, and pegs.
b) Create disks with central holes.
12.8 Use the blow molding example as a starting point for the following.
a) Create an animation of the blow molding sequence. Is it possible to interpolate between time steps? How would you do this?
b) Create the second half of the parison using symmetry. What transformation matrix do you need to use?
12.9 Start with the stock visualization example presented in this chapter.
a) Modify the example code to use a ribbon filter and linear extrusion filter as described in the text. Be careful of the width of the generated ribbons.
b) Can you think of a way to present high/low trade values for each day?